
Świat jaki znamy, nieustannie się zmienia. Co chwilę pojawiają się nowinki technologiczne, które wypychają z rynku stare technologiczne graty. Zmiany technologiczne mogą stanowić wyzwanie, ale zachodzą one obecnie szybciej niż kiedykolwiek w historii. Jednym z zasadniczych czynników który się do tego przyczynił jest cyfrowa transformacja. Właściwie to żyjemy już w cyfrowej erze. Dzięki wynalezieniu Internetu staliśmy się połączeni z prawie nieograniczonym źródłem informacji. Dalej przyszły kolejne technologie takie jak telefonia 2/3/4G i w końcu smart-fon, które sprawiły że jesteśmy bardziej połączeni z innymi ludźmi niż kiedykolwiek wcześniej. Ludzie żyją już ze swoimi telefonami, czytają na tabletach, a podwórkowy trzepak jako miejsce socjalnych schadzek został zastąpiony laptopem. Bycie częścią tej cyfrowej ery jest już de facto obowiązkiem.
Nowe technologie przynoszą korzyści już nie tylko nam jednostkom, ale także całym społecznościom a także przedsiębiorstwom. Te z kolei widząc zapotrzebowanie, ciągle oferują kolejne technologiczne gadżety. Gospodarka cyfrowa nabiera poważnych kształtów i zaczyna podważać konwencjonalne koncepcje dotyczące struktury przedsiębiorstw, sposobu interakcji między nimi oraz sposób, w jaki konsumenci uzyskują usługi, informacje i towary.
Kręgosłupem gospodarki cyfrowej jest hiperłączność, a ta sama w sobie oznacza rosnącą wzajemną zależność ludzi, organizacji i maszyn. Gospodarka światowa również przechodzi transformację cyfrową i toczy się w zawrotnym tempie. Zmieniają się więc kanały dystrybucji, zmieniają się modele biznesowe, zmienia się także metody zbierania, przechowywania i przetwarzania danych, i nie tylko tych finansowych. U podstaw cyfrowej transformacji nie leży tylko internet i jego internetowe “jednorożce”. Nowe technologie telefonii komórkowej 5G i nadchodzący Internet Przedmiotów (IoT) nadadzą nowych szybkości globalnej gospodarce. Pojawiają się nowe gałęzie przemysłu zajmujące się przetwarzaniem coraz to większej ilości danych, a te jak wiemy są ropą XXI wieku. Z kolei agresywne wykorzystywanie danych przekształca modele biznesowe, ułatwiając im tworzenie nowych produktów i usług, tworząc nowe procesy, generując coraz to większą użyteczność i wprowadzając nową kulturę zarządzania.
W 2009 roku na rynku potencjalnych rozwiązań do zarządzania danymi pojawiła się technologia blockchain, która rośnie jak grzyby po deszczu. Wiele z projektów zostało stworzonych do różnych celów i ekosystemów, a liczba potencjalnych zastosowań w przemyśle ciągle rośnie. Od czasu wprowadzenia Bitcoin blockchain do września 2020 roku w repozytorium Githuba znajduje się aż 11 900 aktywnych łańcuchów blokowych. Każdy z tych projektów ma swój własny protokół, realizowany jest przy użyciu konkretnych języków programowania oraz wiele z nich posiada bardzo ciekawe i innowacyjne rozwiązania. Innowacyjny “wyścig zbrojeń” w blockchain trwa. Pojawiają się już zaawansowane technologicznie projekty które dostarczają rozwiązań oferujących inter-operacyjność, jak również pomosty technologiczne do realnego świata w postaci usług oracles. Branża zaczęła w końcu przyciągać oczy dużych globalnych graczy. I tak już w 2015 r. Światowe Forum Gospodarcze (WEF) zidentyfikowało technologię łańcuchów blokowych jako jeden z sześciu megatrendów w nowym raporcie, którego celem jest nakreślenie oczekiwanego przejścia do bardziej cyfrowego i połączonego świata. Z kolei Santander oszacował w swoich analizach The FinTech 2.0 Paper, iż technologia rozproszonych ksiąg rachunkowych mogłaby zaoszczędzić bankom sporo pieniędzy poprzez wyeliminowanie centralnego zarządzania i obejścia powolnych, kosztownych sieci płatności. Same technologie blockchain mogą do 2022 obniżyć koszty infrastruktury banków o 15-20 mld dolarów rocznie, jak również pozwolić znacznie zmniejszyć ilość papierkowej roboty związanej z obsługą aktywów i sprawić, że procesy handlowy będzie bardziej wydajny i opłacalny zarówno dla firm, jak i dla ich klientów. Z kolei procesy czasy rozliczeń transakcyjnych mogą ulec skróceniu z dni do minut, zbliżając się niemal do zera. Blockchain oferuje więc możliwości i technologie transformacji globalnego finansowania handlu.
Deloitte podobnie jak WEF przewiduje że do roku 2025 10% globalnego PKB będzie przechowywane na blockchain. Instytucje finansowe będące głównym graczem globalnej gospodarki powolutku zaczynają lokować się w czołówce deweloperów i użytkowników aplikacji technologii łańcuchów blokowych. Powstają kolejne narzędzia walidacyjne w celach zwalczania nieuczciwych podmiotów. Zmienią się też niewątpliwe usługi audytu, który istnieje de facto tylko dlatego,że firmy nie mają zaufania do swoich księgowych. Banki centralne też już wkroczyły do wyścigu i będą w niedługiej przyszłości rozszerzać swoją działalność na hurtowe i detaliczne systemy płatności oparte o waluty cyfrowe Banku Centralnego (CBDC). Tak więc blockchain zadomowił się w świecie szybko i już z nami pozostanie. Możemy więc być pewni że zrewolucjonizuje archaiczne już systemy gromadzenia i przetwarzania danych. Bo przecież blockchain to nic innego jak jedna wielka księga rachunkowa (ledger), z ta różnicą, że występuje ona w wersji zdecentralizowanej.
LEDGER klasycznie
Aby zrozumieć czym jest łańcuch bloków należałoby zacząć od zrozumienia podstawy zapisu działalności gospodarczej. Wykorzystanie ksiąg rachunkowych do zapisu wymiany najczęściej aktywów, takich jak pieniądze i majątek pomiędzy stronami istnieje odkąd istniała na świecie wymiana handlowa. Głównym celem księgi rachunkowej było służenie jako medium do rejestrowania transakcji finansowych, do których każdy może mieć łatwy dostęp w dowolnym momencie. Na początku były to zapewne konta osobowe dłużników. I tak już w Mezopotamii odkryte zostały starożytne dokumenty w których odnotowane były listy wydatków i towarów otrzymanych, jak również sprzedawanych. Księgi te były przechowywane w świątyniach, które w tamtych czasach były uważane za banki. Do około IV BC starożytni Egipcjanie i Babilończycy posiadali już systemy audytu dla ruchu w magazynach i poza nimi. Obejmowały one ustne/pisemne sprawozdania z przeprowadzonej kontroli, ponieważ opodatkowanie wymusiło potrzebę rejestrowania płatności. Podwójna księgowość wpisów pojawiła się pierwszy raz w średniowiecznej Europie, kiedy ta zaczęła przechodzić na gospodarkę pieniężno-kredytową w XIII wieku. Powstała ona w celu nadzorowania jednoczesnych transakcji finansowanych wynikających z kredytów bankowych. Zostały stworzone zasady zapis debetowe i kredytowe dla każdej transakcji. Nowoczesne metody księgowe, do których przywykliśmy zaczęły się rozpowszechniać wraz z profesjonalizacją dziedziny księgowości, która rozpoczęła się w XIX wieku.

Source: https://sites.rootsweb.com/~nygreen2/christopher_watrous_-_ledger_book.htm
W nowoczesnej rachunkowości księga rachunkowa to księga (lub zapis) służąca do zbierania historycznych danych transakcyjnych z dziennika i organizowania zapisów według kont. Charakteryzujący się ona ujęciem wszystkich operacji gospodarczych dokonywanych przez podmiot. Metoda podwójnego księgowania zapewnia, że księga główna przedsiębiorstwa jest zawsze zbilansowana. W analogii można o tym myśleć jako o książeczce czekowej, która musi zawsze znajdować zawsze się w równowadze między kwotą kredytu (po lewej) a kwotą debetu (po prawej), zgodnie z zasadą podwójnego zapis (zapisy przeciwstawne). Jest to nic innego jak baza danych ewidencji i informacji finansowych spółki. Dzieli się ona dalej na różne konta reprezentujące aktywa, pasywa, kapitał własny, przychody, wydatki, odpisy itp.
Aktywa to wszelkie zasoby, które są własnością przedsiębiorstwa i wytwarzają wartość. Mogą one obejmować środki pieniężne, zapasy, nieruchomości, wyposażenie, znaki towarowe i patenty. Pasywa to bieżące lub przyszłe zobowiązania finansowe, które przedsiębiorstwo musi spłacić. Mogą one obejmować zobowiązania krótkoterminowe takie rzeczy jak wynagrodzenia, raty kredytowe, bieżące wydatki operacyjne, podatki, a przyszłe zobowiązania mogące obejmować takie rzeczy jak kredyty bankowe lub linie kredytowe, hipoteki lub leasing. Z kolei kapitał własny jest różnicą pomiędzy wartością aktywów a całymi zobowiązaniami przedsiębiorstwa. Jeśli przedsiębiorstwo ma więcej zobowiązań niż aktywów, może mieć ujemny kapitał własny. Przychody są przychodami przedsiębiorstwa, które pochodzą ze sprzedaży jego produktów i/lub usług. Mogą one obejmować sprzedaż, odsetki, tantiemy lub inne opłaty, które firma pobiera od innych osób lub firm. Z kolei wydatki składają się z pieniędzy płaconych przez przedsiębiorstwo w zamian za produkty lub usługę. Wydatki mogą obejmować czynsz, media, podróże i posiłki.
Proces rejestrowania i przetwarzania danych finansowych określany jest mianem cyklu księgowego, będącego zbiorowym procesem identyfikacji, analizy i rejestracji zdarzeń księgowych przedsiębiorstwa. Jest to standardowy wielo-stopniowy proces, który rozpoczyna się w momencie wystąpienia transakcji i kończy się wraz z jej ujęciem w sprawozdaniu finansowym. Kluczowymi etapami cyklu księgowego jest rejestracja zapisów w dziennikach, księgowanie w księdze głównej, obliczanie próbnych bilansów, dokonywanie korekt zapisów oraz tworzenie sprawozdań finansowych zarówno dla urzędów, jak i zarządów przedsiębiorstw. Przykładowy schemat jak poniżej.
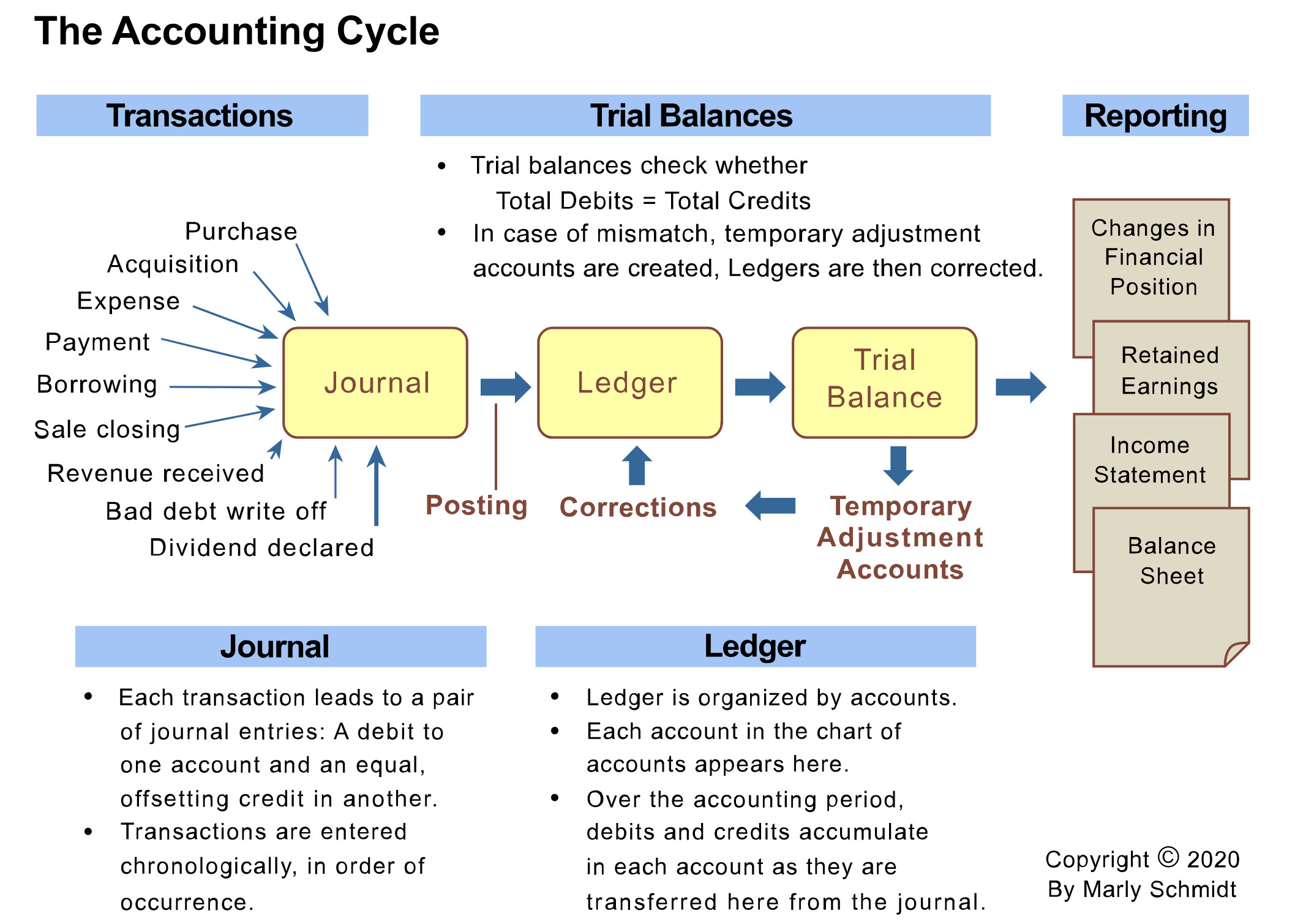
Source: https://www.business-case-analysis.com/ledger.html
W obecnej cyfrowej dobie konwencjonalna księgowość jest skomputeryzowana, a do tworzenia całego cyklu księgowego służą wyspecjalizowane programy, które zarządzają całym procesem (np. Sage, Chorus), a do gromadzenia i przetwarzania danych używają baz danych. Praktycznie każdy program, czy nawet algorytm, operuje na różnego rodzaju danych. Dane te muszą być w jakiś sposób grupowane i przechowywane. Służą do tego struktury danych. Strukturę danych można postrzegać jako swego rodzaju pojemnik na dane, który gromadzi informacje i układa je w odpowiedni sposób. Struktura danych to specjalistyczny format używany do przechowywania i organizowania informacji. Jest ich wiele rodzajów, od prostych tablic, stosów, list, drzew, grafów po bardziej zaawansowane struktury obiektowe.
Standardową bazę danych można porównać w analogii do albumu zdjęć (których nie chciałbyś utracić) albo segregatora, w którym przechowywane są ważne dokumenty (np. umowy, kwity podatkowe). Konto bankowe z cyfrowym zapisem środków, oraz historii ich transakcji to bardziej cyfrowa baza danych. We wszystkich przypadkach dane te są przechowywane w jednym miejscu, posiadają kompaktowy format, oraz zarządza nimi jakaś jednostkowa podmiotowa (osoba, firma itd), w skrócie jedna centralna osobowość. Budowanie takich scentralizowanych systemów jest dość szybkie i również tanie (porównując do innych o czym później). Jednakże jako, że są one centralizowane to istnieje opcja, że ktoś może tymi danymi manipulować. Nie jest to łatwe ale (np. legislacja) nie jest to szalenie trudne, wystarczy pogrzebać w bazie danych i rekordy się pozmieniają.
BLOCKCHAIN LISTA
W 2008 świat usłyszał o technologii łańcucha bloków, blockchain. Struktura ta znana jest od co najmniej 1991 roku, jednakże to za sprawą pierwszej kryptowaluty – Bitcoina – stała się globalną gwiazdą. Zastosowanie technologii łańcucha bloków jest jednak znacznie szersze niż kryptowaluty i dotyczy rozproszonych rejestrów, ksiąg rachunkowych transakcji giełdowych czy cywilno-prawnych. Jednym z potencjalnych wykorzystań jest też Internet Rzeczy (IoT). IBM będący jednym z pionierów rozwoju tej technologi (np. Hyperledger) tak definiuje blockchain:
“Blockchain to współdzielony, niezmienny ledger (baza danych), która ułatwia proces rejestrowania transakcji i śledzenia aktywów w sieciach biznesowych. Aktywa te mogą być materialne (dom, samochód, gotówka) lub niematerialne (własność intelektualna, patenty, prawa do kopiowania, loga). Praktycznie wszystko co ma wartość, może być śledzone i być przedmiotem obrotu w sieci łańcucha blokowych, zmniejszając tym samym ryzyko i obniżając koszty dla wszystkich zainteresowanych”. – Blockchain for Dummies, IBM
The blockchain is an incorruptible digital ledger of economic transactions that can be programmed to record not just financial transactions but virtually everything of value. – Don Tapscott – Blockchain Revolution
Aby zrozumieć czym jest blockchain, w dużym uproszczeniu określany mianem łańcucha bloków, należy zrozumieć naturę tej struktury danych. Z punktu widzenia laika w gruncie rzeczy nie jest to takie proste, jakby się mogło wydawać, że jest to ciąg bloków połączony łańcuchem.
Najprostszym sposobem na zrozumienie czym jest blockchain jest jego wizualizacja poprzez przybliżoną formę struktury danych znanej jako Lista Połączona. Struktura ta wykorzystuje inną istotną strukturę: Wskaźniki. Są to zmienne, które przechowają adres innej zmiennej (wskazują na położenie innej zmiennej).
Lista połączona to liniowy sposób organizowania i przechowywania danych, gdzie każdy pojedynczy element/węzeł/block reprezentuje inny obiekt (posiada w sobie dane różnych typów), oraz łącze do następnego bloku, które realizowane jest właśnie za pomocą wskaźnika. Listy połączone są więc strukturą sekwencyjną bloków, gdzie każdy block obok danych posiada w sobie także wskaźnik, który wskazuje na następnego w liście. W ten sposób uzyskuje się funkcje wskazania. Ostatni węzeł, posiada wskaźnik zerowy, co oznacza, że nie ma on żadnej przypisanej wartości. Koncepcyjna wizualizacja listy połączonej przedstawiona jest poniżej.

Source: https://medium.com/@zhaohuabing/hash-pointers-and-data-structures-f85d5fe91659
Blockchain jest zasadniczo podobny do wyżej opisanej listy połączonej, ale istnieje pomiędzy nimi kilka różnic. W blockchain, podobnie jak w przypadku połączonej listy, każdy blok jest połączony ze sobą, ale kierunek wskazywania wskaźnika jest przeciwny. Wskazanie to pozwala na identyfikację poprzedniego bloku, i w ten sposób w blockchain można śledzić poprzednie bloki od bieżącego aż do pierwszego bloku łańcucha, nazywanego blokiem genezy (Genesis). Najważniejszą różnicą obu struktur jest jednak to, że łańcuch blokowy zamiast zwykłego wskaźnika, używa wskaźnika hashowego (Hash Pointer). Ten wskaźnik skrótu podobny jest do zwykłego wskaźnika, ale zamiast tylko podawać adres poprzedniego bloku, zawiera także skrót/hash danych zawartych w poprzednim bloku. Używa do tego funkcji mieszkającej/haszującej.
Zasadniczo blockchain to ciąg bloków, gdzie każdy z nich zawiera swoją własną unikalną wartość skrótu, jak również unikalny skrót/hash dla poprzedniego bloku. Skrót ten wyliczany jest dla danych z nagłówka z poprzedniego bloku, i pozwala to określić/sprawdzić czy transakcje zapisane w poprzednim bloku nie zostały naruszone. Kolejną ważną różnicą jest to, że w liście połączonej dane przechowywane w węźle mogą ulec zmianie, a całe węzły mogą zostać dodane czy też usunięte w dowolnym miejscu listy. W łańcuchu bloków jakiekolwiek zmiany (danych/transakcji) doprowadziłaby do ponownego przeliczenia hashów dla wszystkich bloków do przodu aż do bieżącego bloku. Z tego powodu usuwanie i modyfikacja bloków nie jest możliwa, a nowy block może być dodany jedynie na końcu łańcucha (listy). Tak właśnie działa łańcuch bloków.
Konwencjonalne struktury danych takie listy połączone zostały zaprojektowane jako scentralizowane bazy danych, i nie opisują one metod zapewniających istnienie pojedynczej wersji danej struktury danych. Nie jest trudnością więc przepisać historię transakcji w takich strukturach, albo też stworzyć alternatywną listę/kopię, która jest tak samo ważna jak oryginał. Technologia blockchain rozwiązuje problem decydowania o tym, który z wersji łańcucha jest prawidłowa, oraz kto dodaje kolejny blok. Służą do tego algorytmy konsensusu/zgody. Blockchain jako struktura danych został pomyślany jako struktura rozproszona, kontrolowana właśnie przez te zdecentralizowane algorytmy konsensusu. Algorytmy te łączą w sobie kryptografię i bodźce ekonomiczne w celu egzekwowania poprawności i niezmienności. To własnie mechanizm zdecentralizowanego konsensusu odróżnia publiczne blockchainy od poprzedzających je technologii, takich jak listy połączone czy też współdzielone bazy danych. Bez dalszego kontekstu społecznego, nie jest możliwe podjęcie decyzji, która wersja jest poprawna, praz który blok jest ten właściwy do dodania.
Dane zostają zapisane na rozproszonym rejestrze i rozchodzą się na tysiące węzłów, czyniąc cenzurę i próby blokad tych usług skomplikowanym przedsięwzięciem.
NAGŁÓWEK BLOKU DANYCH
Blockchain to więc ciągle rosnąca lista połączonych rekordów, zwanych blokami. Blok jest określeniem zbioru danych, który zawiera określoną liczbę zapisów z transakcjami. Rozmiar takiego bloku jest ściśle określony i uzależniony od konkretnej implementacji, oraz charakterystyki danej kryptowaluty. Przykładowo wielkość bloku Bitcoin może wynosić maksymalnie do wartości 1 MB, co wynika bezpośrednio ze specyfikacji protokołu Bitcoin.
Struktura danych takiego blogu składa się z sekcji nagłówkowej (header) i sekcji transakcji (body), przy czym sekcja nagłówka zawiera także wartość skrótu dla wszystkich transakcji z tego bloku. Zarówno nagłówek i sekcja transakcyjna/danych nie są ściśle określone i zależą od konkretnej implementacji, zapisanej w protokole danej kryptowaluty. Nagłówki różnią się od implementacji, ale zasadniczo zawarte w nich są te same rodzaje informacji. Dla przykładu, poniżej przedstawiona jest zawartość informacyjna nagłówka dla waluty Bitcoin, mająca całkowitą wielkość 80 bajtów, a w nawiasie podane są wielkości dla poszczególnych rekordów. Z kolei nagłówek bloku ETH jest już o wiele większy.
- Numer wersji protokołu – (4 bajty);
- Znacznik czasu (timestamp) w formacie UNIX – (4 bajty);
- Znacznik/Cel trudności (Difficulty target) – (4 bajty);
- Nonce – (4 bajty)
- Hash poprzedniego bloku – (32 bajty);
- “Drzewo skrótów” Merkel (Merkel root) dla danego bloku – (32 bajty).
Numer wersji mówi, która protokołu została użyta do wykopania bloku, czyli określa jakie zasady obowiązują w walidacji danego bloku. Ogólnie mówiąc, protokół to zbiór zasad, które określają na jakich warunkach mogą być przeprowadzane transakcje w sieci oraz na jakich warunkach są tworzone nowe coiny. Co jest ważne, te zasady nie mogą zostać zmienione, chyba że za zgodą ogółu. Dostępne są tam różne wersje blokowe, które stanowią część historii rozwoju Bitcoina. Zmiany wersji są implementowane poprzez BIP (Bitcoin Improvement Protocol). Obecna wersja to 4, a bloki wykopane według innej są odrzucane. Znacznik czasu jest czasem mierzonym wg. reprezentacji Unix (liczba sekund, które upłynęły od stycznia 1970). Znacznik czasu rozpoczyna się w momencie, gdy górnik rozpoczął haszowanie nagłówka, i jego wartość nie może znacząco odbiegać od czasy wydobycia ostatnich bloków.
Cel trudności to zakodowana wersja trudności docelowej. Oznacza to że hash aktualnie kopanego bloku musi mieć wartość nie większą niż cel trudności, określany w liczbie zer wiodących w skrócie, np. blok 650933 = 00000000000000000009b4f9be552c39bfd42c75c2e5b00eab1de0257de3509b. Próg ten jest zmieniany i zależy od całościowej siły obliczeniowej (#hashrate) wszystkich górników. Górnicy haszują aktualny blok i porównują jego wartość z hashem trudności. Jeżeli jest ona większa niż hash trudności to szukają dalej. Wartość hashu dla danych transakcyjnych z danego bloku jest stała, tak więc w nagłówku dodana jest zmienna losowa Nonce, której wartość górnicy zmieniają aby wyliczać nowe wartości hash. Ktokolwiek pierwszy znajdzie taką wartość (magic number X), która sprawi że wyliczony hash jest mniejszy niż hash trudności [ hash (block + X) < hash (target) ], staje się walidatorem bloku. W nagrodę dostają coiny za wydobycie bloku, plus wszystkie opłaty transakcyjne. Tylko jeden górnik (albo zespół) może wykopać blok. Reszta wyliczała skróty za darmo, znaczy się przepalała koszty elektryczne za darmo. Próg trudności jest tak wyliczany aby średni czas kopania bloku wynosił 10 minut. Szukanie “magic number” to główna czynność, w którą górnicy angażują się i rywalizują pomiędzy sobą górnicy, próbując rozwiązać kryptograficzną zagadkę, określoną właśnie celem trudności. Im większa trudność, tym dłużej trwa uzyskanie poprawnego hasha. Dla przykładu historyczne hashe z blockchainu Bitcoina:
Blok 000010 = 000000002c05cc2e78923c34df87fd108b22221ac6076c18f3ade378a4d915e9Blok 050000 = 000000001aeae195809d120b5d66a39c83eb48792e068f8ea1fea19d84a4278aBlok 250000 = 000000000000003887df1f29024b06fc2200b55f8af8f35453d7be294df2d214Blok 650933 = 00000000000000000009b4f9be552c39bfd42c75c2e5b00eab1de0257de3509b
Hash poprzedniego bloku to skrót wyliczany dla danych z nagłówka dla poprzedniego bloku. Jest to więc hash wszystkich danych z poprzedniego bloku, czyli de facto hash całej historii łańcucha bloków (Każdy blok używa haszu z poprzedniego bloku do skonstruowania swojego własnego haszu. Hash bloku jest unikalnym identyfikatorem. Nie istnieją dwa bloki z tym samym haszem. Haszowanie pełni on bardzo ważną funkcję w łańcuchu blokowym, jako że zabezpiecza że informacje te nie mogą być modyfikowane bez konieczności modyfikowania poprzednich bloków. Zmiana wartości skrótu poprzedniego bloku, wywołałaby efekt lawinowy, co oznacza, że wymaga to zmiany innych poprzednich wartości skrótu. Wartym zauważenia jest, że obecnie jest już ponad 650 000 bloków. Wymagałoby to dużej ilości mocy obliczeniowej. Teoretycznie jest to możliwe, ale wymagałoby tak zwanego ataku 51%. Odwracanie wszystkich transakcji jest więc trudne do wykonania na łańcuchu blokowym z powodu #haszu nagłówka bloku. W rzeczywistości górnicy mogą odeprzeć taki atak poprzez rozwidlenie (fork) łańcucha bloków. Konsensus jest więc kluczem do zachowania ważnych informacji w łańcuchu blokowym, a funkcja łączenia hashów zapewnia bezpieczeństwo i odporność blockchain na manipulacje.
Każdy blok w łańcuchu zawiera podsumowanie wszystkich transakcji w bloku. W większości kryptowalut (np. Bitcoin lub Ethereum) jest to realizowane przy użyciu struktury drzewa Merkle’a. Merkle Tree (znane również jako binarne drzewo hash) jest strukturą danych używaną do efektywnego podsumowania i weryfikacji integralności dużych zbiorów danych. Struktura ta jest drzewem binarnym zawierającym kryptograficzne skróty wszystkich transakcji. Drzewa Merkle’a są używane do tworzenia ogólnego cyfrowego odcisku palca dla całego zestawu transakcji, zapewniając bardzo skuteczny proces weryfikacji, czy transakcja jest zawarta w bloku. Dane znajdujące się na “gałęziach” drzewa mieszają się ze sobą tworząc indywidualne skróty. Te skróty łączą się z innymi, aż do chwili, gdy pozostanie tylko jeden. Nazywany jest on korzeniem drzewa.
Drzewo Merkle’a jest budowane poprzez rekurencyjne wyliczanie skrótów dla pary węzłów (w tym przypadku transakcje), aż do momentu, gdy pojawi się tylko jeden hasz, zwany korzeń Merkle’a. Merkle Root to sumaryczny skrót/hash wyliczany dla wszystkich transakcji w bloku. Jest on pojedynczym identyfikatorem dla całego drzewa transakcji. Co ważne jest on wyliczany z skrótów poszczególnych transakcji. Przykładowo mamy 4 transakcje A,B, C, D (w rzeczywistości jest ich dużo więcej np. 2025 dla bloku 650934). Wyliczane są dla nich skróty hA i hB, oraz dla hC i hD, gdzie hA dla Bitcoina = SHA256(SHA256(Transakcja A)). Pary skrótów są dalej łączone i wyliczany jest dla nich skrót zbiorczy. Następnie, proces ten jest powtarzamy aż do momentu, gdy pozostanie nam tylko jeden hash, ostatni haszysz będący naszym korzeniem merkle’owym. Informacja ta jest przechowywana w nagłówku bloku w każdym bloku łańcucha blokowego. W ten sposób transakcje są podsumowywane w każdym bloku. Nie ma znaczenia ile transakcji jest zawartych w pojedynczym bloku, zawsze będą one podsumowane 32 bajtowym haszem. Przykładowo dla blok 650933 = bba664090f0b5cd5284a6012dc67ab018790166298cddaba5671ee0fed669b6d.

Source: https://www.oreilly.com/library/view/mastering-bitcoin/9781491902639/ch07.html
Ponieważ wszystkie gałęzie w drzewie zależą od innych gałęzi, nie da się zmienić jednej gałęzi bez zmiany innych. Jeśli zostanie zmieniona nawet pojedyncza gałąź (jedną transakcję) to zmieni się jej hash, a to spowoduje że zmieniony zostanie hash z pary, a to wymusi też zmiany innych hashy w górę drzewa. Drzewo to konstruowane jest od dołu do góry poprzez parowanie każdej gałęzi, jak przedstawione na poniższym przykładzie. Haszowanie każdej transakcji zapewnia, że żadna z tych transakcji nie może być modyfikowana bez modyfikowania całego nagłówka bloku. Funkcja ta po raz kolejny dostarcza/zapewnia bezpieczeństwo bloku, przez co blok jest odporny na manipulacje. Podsumowując struktura danych drzewa Merkle utrzymuje integralność danych w łańcuchu blokowym. Jeśli jeden szczegół w dowolnej transakcji lub kolejność transakcji ulega zmianie, zmienia się również Merkle Root.
Podsumowując nagłówek bloku podsumowuje cały blok, pola w nagłówku dostarczają unikalnych szczegółów dotyczących bloku, a funkcja haszowanie sprawia że są one niemożliwe do zmiany, przez co blockchain staje się unikalną konstrukcją.
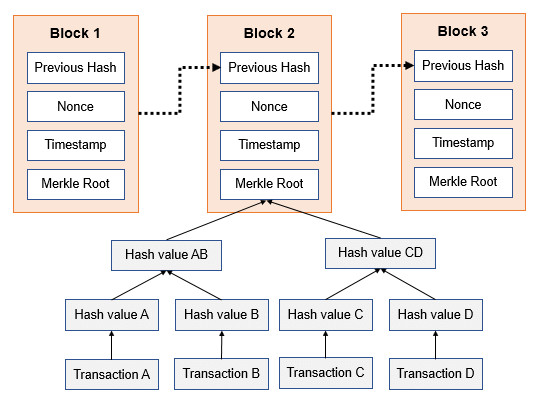
Source: https://www.researchgate.net/publication/339108410_A_survey_on_Blockchain-based_applications_for_reforming_data_protection_privacy_and_security
Część korpusowa bloku składa się z listy wszystkich transakcji, o określonym formacie.
TRANSAKCJE w BLOKU
Blockchain to technologia, która pozwala globalnej społeczności na dzielenie się ledgerem, bez konieczności ufania sobie nawzajem. Informacje zapisane w łańcuchu blokowym mogą mieć dowolną formę, niezależnie od tego, czy chodzi o przekazanie płatności, własność, zwykłą transakcję, czyjąś tożsamość, umowę między dwiema stronami, czy nawet o to, ile energii elektrycznej zużyła lodówka. Format danych i sposób przechowywania danych takiego ledgera może różnić się w zależności od implementacji kryptowaluty, ale jest naszkicowany w konstrukcji protokołu bazowego danego projektu. Wspólną charakterystyką jest jednak to, iż każdy blok zawiera transakcje, które aktualizują stan wspólnego ledgera. Ilość tych transakcji jak już wspominano zależna jest od implementacji danej kryptowaluty. Podobnie sprawa się ma z rodzajem jak i formatem tych danych. Blockchain można de facto porównać do rozproszonej maszyny stanów, gdzie każdy obecny stan jest funkcją działalności jego użytkowników. Wszystkie projekty kryptowalutowe rozpoczynają się od stanu genezy (genesis state), a następnie każdy blok zawiera transakcje, które przenoszą ten stan do przodu. Pierwszym przypadkiem zastosowania technologii blockchain jest pieniądz cyfrowy: Bitcoin, kolejnym bardzo ważnym zastosowaniem były inteligentne kontrakty w sieci Ethereum.
Warto tutaj nakreślić różnicę pomiędzy aktualizacją zwykłej bazy danych a takową w łańcuchy bloków. W pierwszym przypadku jedno zdarzenie/transakcja aktualizuje jedną tabelę danych na jednej maszynie (serwer/komputer), podczas gdy pojedyncze zdarzenie w blockchain aktualizuje tabelę danych na każdej podłączonej do niego maszynie na planecie. Każda nowa transakcja zmienia wiec stan tego rozproszonego komputera, bo tak trzeba traktować de facto technologię blockchain. Cecha ta została jasno i wyraźnie uwidoczniona w krypto-projekcie waluty Ethereum, gdzie sieć komputerów pracuje jako jedna wielka globalna wirtualna maszyna, operująca na tej samej rozproszonej strukturze danych, łańcucha bloków ETH. Np. w danym momencie, łańcuch blokowy Ethereum definiuje aktualny stan komputera na świecie. Każda transakcja jest w efekcie komendą, a “wykonanie” wszystkich tych komend prowadzi do stanu, który jest stanem sieci Ethereum.
Każda transakcja jest pojedynczym zdarzeniem, które jest dozwolone przez dany protokół, a mówią o łańcuchu bloków jako o strukturze danych, transakcja jest więc tylko zdarzeniem, które aktualizuje przechowywane w tej strukturze dane.
Source: https://bitcoin.org/pl/co-potrzebujesz-wiedziec
Najprostsza jednostka transakcji stosowana we wszystkich sieciach typu blockchain, nazywana krypto-walutą lub tokenami. Mówiąc w wielkim uproszczaniu transakcje są to płatności na blockchainie, którego obecny stan pozwala sprawdzić kto ile ma. Transakcje pozwalają więc posiadaczom wydawać ich ₿ – Satoshis. Płatności te odbywają się poprzez przesyłanie środków/danych pomiędzy adresami publicznymi. W gruncie rzeczy blockchain jest zapisem transakcji, w której każda płatność jest dokładnie odnotowana wraz z tzw. adresem portfela nadawcy i odbiorcy, datą, godziną oraz kwotą. Aby transakcja z danego adresu mogła zostać wykonana, musi zostać podpisana przez odpowiedni klucz prywatny. Klucze te przechowywane są w kryto-portfelach. W przeciwieństwie do standardowych portfeli (który przechowuje pieniądze w środku), zawartość krypto-portfela jest na świecie i każdy może zobaczyć ile dany adres posiada, ale żeby te środki/tokeny odblokować to trzeba mieć do tego klucz prywatny. Z tej różnicy często bierze się mylne rozumienie, że ktoś trzyma coiny na portfelu. Coiny są cały czas trzymane na blockchainie, portfel poprzez przechowywanie naszego klucza prywatnego, umożliwia nam tylko do nich dostęp. Wraz ze stratą portfela, nie tracimy dostępu do naszych tokenów (pod warunkiem że mamy ich kopie). Tak więc możemy mieć do nich dostęp z wielu aplikacji portfela.
Wszystkie transakcje w blockchain są przechowywane stale i publicznie w sieci, co oznacza, że każdy może sprawdzić saldo i transakcje zawarte przez dowolny adres. Transakcje (TX) w blockchain są podwójna wymianą zapisów księgowych (double-entry exchanges), które są rejestrowane w księdze głównej blockchain. Każda transakcja składa się z kilku części, które umożliwiają zarówno te proste jak i bardziej zaawansowane płatności. Transakcja blockchain ma następujące podstawowe parametry:
- Input (TxIn) – wejście transakcji, czyli adres publiczny, z którego wysyłamy środki;
- Output (TxOut) – wyjście transakcji, czyli adres publiczny odbiorcy transakcji;
- Amount – wartość wykonywanej transakcji, czyli jaką kwotę w tokenach wysyłamy;
- Transaction Id (TxID) – identyfikator, który jednoznacznie identyfikuje naszą transakcję.
Wszechświat blochain można podzielić na dwie główne architektury prowadzenia ewidencji dla transakcji wyjściowych:
- Transaction-based ledger – Model UTXO (Unspent Transaction Output), czyli księga transakcyjna;
- Account-based ledger – Model oparty na tradycyjnych księgach rachunkowych, gdzie aktualizowany jest bilans.
Model UTXO został po raz pierwszy wykorzystany przez Bitcoin i używany przez wiele innych walut kryptograficznych wywodzących z Bitcoin, np. Bitcoin Cash, Zcash, Litecoin, Doge, Dash, Z kolei Ethereum i inne platformy inteligentnych kontraktów korzystają z modelu konta/balansu. Inne blockchainy to przykładowo EOS, Tron czy XRP też od Ripple.
UTXO
Jest to model, który odzwierciedla realną gotówkę, przez co stara się zapewniać prywatność, a przy tym pozostaje prosty nawet w złożonym środowisku obliczeń rozproszonych. UTXO to skrót od Unspent TX Output. W modelu tym nie ma kont w warstwie protokołów. Zamiast tego, tokeny są przechowywane jako lista wyjść niewydanych transakcji UTXO (unspent transaction outputs). Innymi słowy, kwotę, która jest “niewydana”.
Każde UTXO reprezentuje wyjście z otrzymanej poprzednio przez użytkownika transakcji, a saldo adresu jest sumą niewydanych transakcji (UTXOs). Transakcja w tym modelu zużywają istniejące wyjścia UTXO z wcześniejszych transakcji i generuje nowe wyjścia, które mogą być wydane w ramach przyszłych transakcji. Dla obrazowego zrozumienia, transakcja jest zestawem wejść i wyjść, jak pokazano poniżej. Wyjścia są zawsze nowe, ale wejścia są wyjściami z poprzedniej transakcji. Jeśli wyjście nie jest używane jako wejście dla innej transakcji, to jest ono niewykorzystane (UTXO).

Source: https://www.publish0x.com/little-crypto-guides/understanding-utxo-model-xllxyop
Waluty kryptograficzne UTXO działają w podobny sposób jak fizyczna gotówka, gdzie każde UTXO można porównać w analogi do monet albo banknotów. Podobnie jak banknotu/monety nie można podzielić na mniejsze nominały, tak samo UTXO nie może być dzielone. Nie można wydać części UTXO, więc wydaje się całość albo nic. Warto tutaj podać różnicę pomiędzy banknotami a UTXO. Banknoty są o stałych nominałach, podczas gdy w UTXO nie mają jednak denominacji i reszta może być wydana w dowolnej wielkości. Reszta ta nazywa się address change. Czyli masz nowy adres UTXO (o niższym nominale), gdzie twoja kasa leży nim i czeka na wydanie. Saldo użytkownika w modelu UTXO nie jest zapisywane jako pojedyncza warto, lecz musi być obliczane jako całkowita suma UTXO, które użytkownik posiada.
Każdy UTXO posiada określoną wartość, i musi spełniać dwa kryteria jej wydatkowania.
- Musi zawierać ważny podpis właściciela każdego UTXO, które zużywane jest w transakcji.
- Całkowita suma zużytego UTXOx musi być równa lub większa niż całkowita suma produkowanych przez niego nowych UTXO. Zasada ta zapobiega przypadkowej inflacji.
Wejście transakcyjne w Bitcoinu zawiera tylko hash transakcyjny i indeks wyjścia. Oznacza to, że nie możemy określić, ile transakcja jest warta w całości bez posiadania wszystkich transakcji wejściowych. Żadna transakcja dokonana przy użyciu UTXO nie może być cofnięta, może być jedynie zwrócona przez osobę, która otrzymała środki.
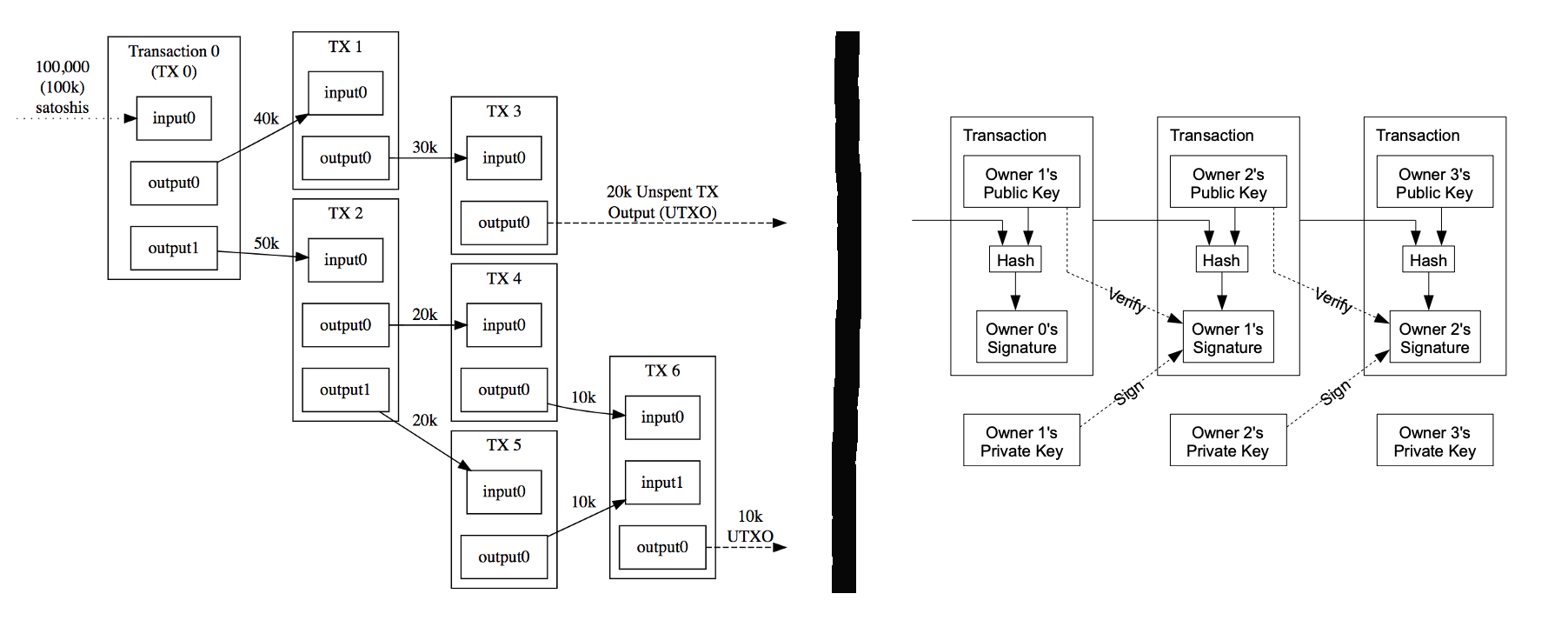
Source: https://medium.com/@sunflora98/utxo-vs-account-balance-model-5e6470f4e0cf / https://medium.com/@jcliff/intro-to-blockchain-utxo-vs-account-based-89b9a01cd4f5
Zaletami modelu UTXO są skalowalność, prostota i zwiększona anonimowość. Model UTXO nie posiada stanu (stateless), a to z kolei oznacza że żadne dwie transakcje nie mogą dotyczyć tego samego UTXO. Pozwala to na przetwarzanie wielu UTXO w tym samym czasie, czyli de facto równoległość transakcji nie musi być sprawdzana. Może to redukować ciężar obliczeniowy walidatorów. Nie jest możliwe, aby dwie transakcje dotyczyły tego samego UTXO. Wynika to z bezstanowego charakteru transakcji UTXO. Transakcje nie odnoszą się do żadnego wejścia poza zużytymi UTXO i odpowiadającymi im podpisami. W modelu UTXO wspierane jest zachowanie ochrony prywatności, gdyż użytkownik używa nowych adresów dla każdej transakcji przychodzącej, w tym do zmiany adresów. Używając nowego adresu za każdym razem, trudno jest definitywnie powiązać różne tokeny z jednym właścicielem. Znacznie trudniej jest także śledzić transakcje, jeśli za każdym razem używane są nowe adresy. Ponieważ wejścia i wyjścia dla transakcji są powiązane kryptograficznie, zwiększa to bezpieczeństwo, a także łatwiej jest uwierzytelnić wszystkie sekwencje transakcji, co z kolei ogranicza ryzyko podwójnego wydatkowania środków.
Transakcje UTXO charakteryzują się prostotą. Wydanie UTXO to wszystko albo nic. Wydanie UTXO to wszystko albo nic. Ponieważ UTXO są niepowtarzalnie oznaczone i całkowicie zużyte przy wydawaniu środków, nie ma możliwości, aby transakcja została powtórnie zrealizowana.
Implementacja portfela UTXO jest złożona, ponieważ w modelu tym nie ma koncepcji konta. Wysyłanie transakcji wymaga wielu czynników, takich jak liczba wejść, które mają być połączone lub które wejścia powinny być połączone, jeśli istnieje wiele możliwych kombinacji. Dlatego to dostawca portfela musi opracować zarządzanie potencjalnym zestawem adresów i sumowanie odpowiednich sald. Wszystko to powyższe jest zaimplementowane w portfelach, tak więc Kowalski aby dokonać transakcję z poziomu portfela nie musi się zastanawiać, ani nawet rozumieć jak działa sieć np. Bitcoina, aby przesłać komuś konkretną sumę. Wystarczy bowiem że poprawnie wpisze adres publiczny odbiorcy (albo zeskanuje kod QR tego adresu), a następnie wybierze domyślnie zaproponowaną przez portfel opłatę transakcyjną i klikając w wyślij właśnie dokonał transakcji, która trafia do kolejki, a jak zostanie zatwierdzona i zapisana w bloku to już na stałe. Rozsądnie jest tez poczekać na 3 potwierdzenia bloków, a po 6 może być już pewien.
Przykładowo masz w portfelu 100PLN, i możesz je mieć w kilku wariantach, np 1×100, 2×50, 5×20, 10×10 albo 20 x 5PLN. Portfel nie potrafi tego przeliczyć, służy jedynie do przechowywania banknotów. Kupując kawę za 5PLN i płacąc nową stówką, dostajesz kawę i kilka różnych banknotów jako reszta. Dla zobrazowania transakcji w krypto, prześledźmy hipotetyczną transakcje BTC pomiędzy Bobem i Alicją. Bob ma w portfelu saldo 4.4 BTC (3+0.8+0.6), ale w trzech UTXO. Alicja jest w posiadaniu 6.75 BTC (5+1.75). Bob przelewa Alicji 3.7 BTC. Sytuacja ta zilustrowana jest poniżej, zarówno dla portfeli przed jak i po transakcji, oraz sam mechanizm transakcyjny. Ponieważ BOB nie ma w całości 3.7 BTC to musi użyć dwóch UTXO (3+0.8). Oba wejścia tworzą nowe wyjście UTXO u Alicji o wartości 3.7 BTC. Ponieważ suma obu użytych UTXO jest większa niż 3.7 BTC to Bob ma stworzony nowe wyjście o wartości 0.1 BTC, gdzie trafia reszta z powyższej transakcji.
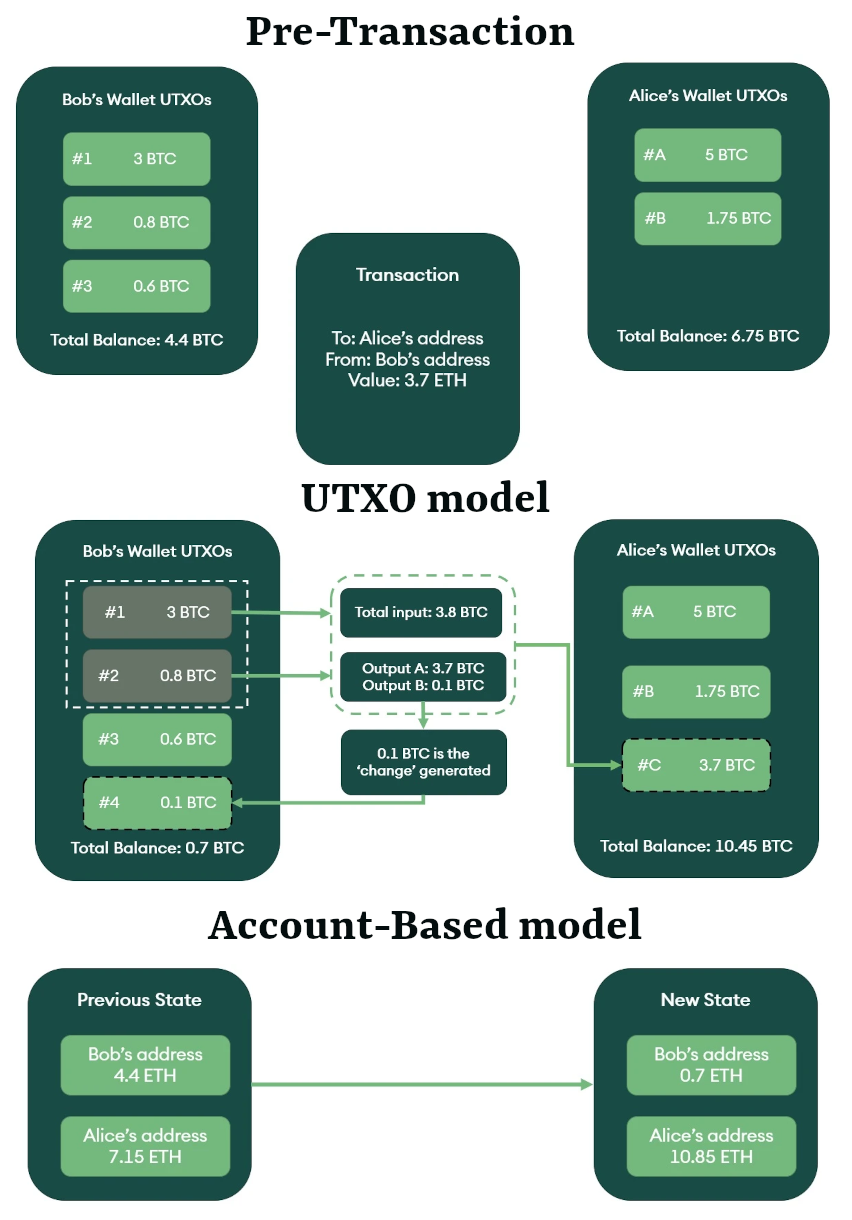
Source: ttps://www.seba.swiss/research/A-Beginner-s-Guide-to-Blockchain-Accounting-Standards
Wadą tego modelu jest to, że możliwości inteligentnego kontraktowania są dość ograniczone w modelu UTXO. Dzieje się to z dwóch powodów: transakcje UTXO mogą być wykonywane równolegle, oraz każdy UTXO posiada kryteria wydatkowania, które dyktują warunki wydatkowania. Może to wymagać podpisów wielu stron, ale nie ma zbyt wielu możliwości odniesienia się do stanu zewnętrznego, takiego jak wyrocznia (oracle).
ACCOUNT BASED MODEL
Jest to standardowy model oparty o bilans całkowity. W analogi można go porównać do modelu rachunku z transakcjami kartą debetową. W modelu tym adresy publiczne są postrzegane podobnie do rachunków bankowych, i są reprezentowane przez łączne saldo, a nie sumę UTXO. W odróżnieniu od modelu UTXO, transakcje są prostymi przelewami środków pomiędzy dwoma adresami publicznymi, gdzie wysłanie środków zmniejsza saldo jednego konta i zwiększa saldo drugiego. Nie ma występuje tam żadna zmian adresów. Wynika z tego że, w przeciwieństwie do UTXO, salda mogą być częściowo wykorzystane.
Model konta mapuje wszystkie konta będące de facto adresami publicznymi na salda, przy czym transakcje to zdarzenia które przenoszą jeden stan blockchain na drugi. Transakcje dokładnie definiują wynikający z nich stan, i dlatego określane są jako posiadające stan. Jest to jedna z ważniejszych różnic pomiędzy UTXO a blokchainami opartymi o model konta na protokole. Konta mogą być kontrolowane albo za pomocą klucza prywatnego, albo inteligentnego kontraktu. Model oparty na kontach jest bardziej efektywny, ponieważ transakcje w systemie opierają się na istniejącym stanie konta, a każda transakcja musi tylko potwierdzić, że konto wysyłające posiada wystarczające saldo, aby dokonać transakcji.
Aby zilustrować niektóre z niuansów wprowadzonych w modelu opartym na rachunku, posłużymy się powyższym przykładem przelewu od Boba do Alizji, gdzie suma transferu to 3.7 ETH. Jako że salda mogą być częściowo wydane w modelu rachunku, to w kolejnym stanie blockchain (po transakcji) z konto Boba zostało odjęte 3.7 i obecny bilans to 0.7 ETH, a konto Alicji zostało zasilone o 3.7 ETH i teraz jej bilans to 10.85 ETH. Aby zapewnić, że transakcje nie będą przetwarzane wielokrotnie, wymagane jest stosowanie Nonce.
Główną zaletą modelu konta jest elastyczność transakcji. Transakcje zależą od istniejącego stanu konta i mogą mieć rozbieżne skutki w oparciu o zewnętrzne dane wejściowe. Dzięki temu takie rzeczy jak zewnętrzne wyrocznie (oracles) i inne logiki mogą wpływać na stan transakcji. Ponieważ inteligentne kontrakty są fundamentalne dla modelu Ethereum, podejście oparte na rachunku pomaga uczynić inteligentne umowy bardziej wyrazistymi i silniejszymi. W przypadku rachunków zgodnych z podejściem stanowym, deweloperzy mają większą elastyczność w tworzeniu aplikacji i inteligentnych umów. Dodatkowo, ponieważ istnieje jedynie wymóg zapewnienia, że rachunek wysyłający posiada wystarczające środki na realizację transakcji, model ten jest znacznie prostszy i w rezultacie występuje duży wzrost wydajności.
Poleganie na “zdarzeniach”, a nie na określonych stanach wejściowych i wyjściowych, stwarza jednak problemy dla tego modelu, ponieważ każda transakcja musi być sprawdzana pod względem dokładności, czy rachunek ma środki na transakcje i czy transakcje nie jest wykonywana równolegle. Może to niepotrzebnie skomplikować model rachunku, poświęcając przy tym pewność w procesie, ponieważ ważność transakcji nie jest potwierdzona do momentu ich ostatecznego wykonania. Ponieważ wynik transakcji zależy od stanu wejścia, należy zachować ostrożność przy równoległym wykonywaniu transakcji. Generalnie, transakcje dotyczące tego samego rachunku będą musiały być wykonywane jedna po drugiej.
Ponadto, modele kont zachęcają do ponownego wykorzystywania adresów, co z reguły jest szkodliwe dla prywatności, ponieważ samo konto łączy transakcje z jednym właścicielem.
EUTXO
Bitcoin i Ethereum wybrały różne modele rachunkowości, ponieważ mają one różne zastosowania. Nowsze standardy rachunkowości w łańcuchach blokowych coraz częściej szukają modeli hybrydowych, tak aby skorzystać z zalet zarówno UTXO, jak i podejścia opartego na modelu rachunku. Do projektów, które już przyjęły albo zamierzają model hybrydowy należą między innymi Cardano, Komodo, czy też Tron.
ŻYCIE w INTERNECIE
Blockchain to tylko struktura danych. Aby mogła być ona używana ( i tym odporna na manipulacje) to musi żyć na internecie, czyli globalnej sieci. Sieć jest to nic innego jak grupa połączonych ze sobą urządzeń (komputery, telefony itp), które wymieniają pomiędzy sobą informacje/dane. Urządzenia te mogą być podłączone lokalnie za pomocą kabla lub też bezprzewodowo. Internet, określany również jako sieć sieci, to z kolei ogólnoświatowy system połączeń między komputerami, działający w oparciu o protokół IP (Internet Protocol). Każde urządzenie w sieci ma swój adres IP. Jest to numer identyfikacyjny komputera lub serwera w sieci, i służy on do prawidłowej komunikacji między urządzeniami. Ma on format zapisu w formie czterech liczb oddzielonych kropkami np. 255.250.50.5, gdzie początkowe liczby oznaczają adres sieci, natomiast końcowe liczby adres hosta, czyli komputera podłączonego do sieci. Adres IP może być stały lub zmienny (czyli dynamiczne przypisywany do komputera każdorazowo po połączeniu z Internetem). Adres IP nie identyfikuje jednoznacznie urządzenia w sieci, ale określa konkretne połączenie w sieci. Adres IP nie jest więc “numerem rejestracyjnym” komputera, jak wielu uważa. Takowym jest MAC (Media Access Control). Jest to adres, który jednoznacznie definiuje interfejs sprzętowy. Reasumując, podstawową różnica między adresem MAC i adresem IP polega na tym, że adres MAC jednoznacznie identyfikuje urządzenie, które chce wziąć udział w sieci, adres IP w unikalny sposób definiuje połączenie sieci z interfejsem urządzenia.
Podstawowym celem tworzenia sieci komputerowych jest współdzielenie zasobów do których możemy zaliczyć dane, pliki, też inne urządzenia jak drukarki. Aby dane zasoby zostały udostępnione, ich właściciel musi wyrazić zgodę na korzystanie z nich przez innych użytkowników. Host (komputer), który udostępnia swoje zasoby czy też usługi nosi nazwę serwer. Urządzenia korzystające z udostępnionych zasobów nazywane są klientami.
Komputery działające w sieci, operują o tzw. architekturę sieci, czyli sposób poleczenia urządzenia. Najczęściej stosowaną architekturą sieci jest scentralizowany model zwany, klient-serwer. Jest to konfiguracja sieci, gdzie istnieje centralny organ/jednostka przechowujący i zarządzający wszystkimi informacjami (serwer), do którego podłączeni są korzystający z tych danych/usług klienci. Serwer jest też jest odpowiedzialny za przetwarzanie danych oraz komunikację pomiędzy poszczególnymi komputerami (klientami) w danej sieci. Wszystkie komputery połączone są bezpośrednio z serwerem i za jego pośrednictwem wymieniają między sobą dane. Jest to model sieciowy, który de facto koncentruje się na udostępnianiu informacji.
Alternatywną architekturą sieci jest model bezpośredniego połączenia pomiędzy komputerami. Model ten nazywany jest Peer-to-Peer (P2P). W sieci P2P mamy do czynienia z połączeniami typu każdy z każdym albo równy z równym. Uczestnicy takiej sieci nazywani są węzłami (nodes) lub rówieśnikami (peers), stąd nazwa peer-to-peer. W takowej konfiguracji nie ma centralnego punktu przechowywania zasobów, a zatem nie ma jednego podmiotu kontrolującego dane zasoby. W praktyce oznacza to, że każdy komputer w sieci może mieć równorzędne uprawnienia. Wymiana zasobów pomiędzy poszczególnymi maszynami nie wymaga pośrednictwa jakiejkolwiek jednostki centralnej (eliminowana jest więc rola pośrednika). Co więcej, każdy z komputerów w sieci P2P sam może pełnić funkcję serwera, lub też być klientem, w zależności od tego, czy węzeł żąda lub świadczy usługi. Każdy węzeł jest traktowany jako równorzędny, co sprawia że P2P jest de facto siecią rozproszonych jednostek, które udostępniają zasoby/dane, bez potrzeby pośredników. Poniżej przedstawione są obie omówione architektury sieci.
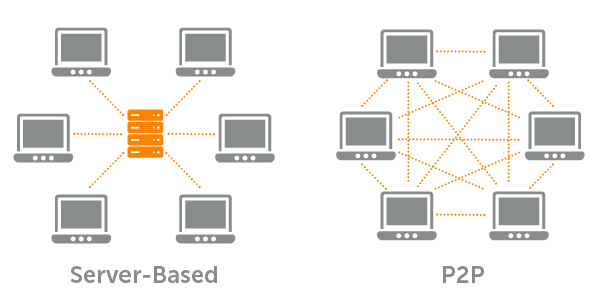
Source: https://www.wowza.com/resources/guides/p2p-unicast-streaming
Jednym z pierwszych i zarazem najsłynniejszych programów do bezpośredniej (P2P) wymiany danych w Internecie był Napster, gdzie każdy internauta, który zainstalował aplikację Napster stawał się częścią wielkiej sieci P2P wymieniającej między sobą dane. Nowszymi i bardzo popularnymi sieciami typu P2P w Internecie są BitTorrent oraz ed2k.
STRUKTURA SYSTEMU DANYCH
Dane podobnie jak sieci mogą mieć różne struktury rozłożenia, jak i zarządzania nimi. W wielu publikacjach istniej podział jedno-wymiarowy na system scentralizowany, zdecentralizowany i rozproszony, jak przedstawiono poniżej.
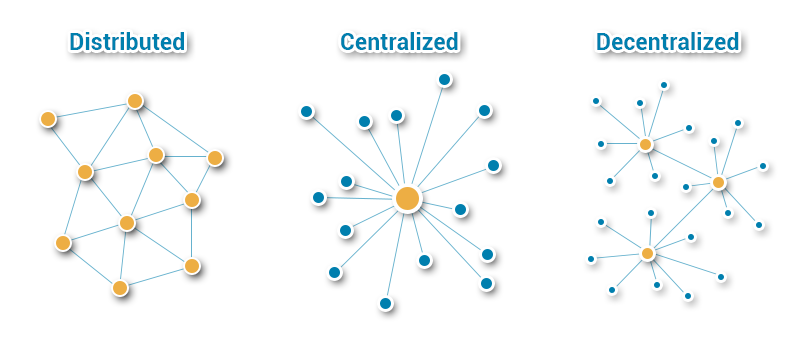
Source: https://steemit.com/cryptocurrency/@quantalysus/choosing-between-centralized-decentralized-and-distributed-networks
System centralny (centralised) to taki gdzie wszystkie dane stanowią zunifikowaną całość, która jest przechowywana na jednym komputerze (węźle). W systemie zdecentralizowanym (decentralised) nie istnieje centralne miejsce przechowywania danych, różne serwery dostarczają informacje do klientów, a serwery te są połączone ze sobą. System rozproszony (distributed) to taki gdzie nie ma żadnych magazynów danych, gdyż wszystkie węzły zawierają te dane/informacje. Są one powielane na wszystkie węzły. Klienci są sobie równi i mają równe prawa.
Jak widać, sieć rozproszona to taka, w której powiązania mogą występować między dowolnymi uczestnikami sieci, w przeciwieństwie do pozostałych dwóch typów sieci, w których dany uczestnik może być powiązany tylko z jednym centrum (sieć scentralizowana) lub z jednym spośród pewnej liczby centrów (sieć zdecentralizowana).
Jednakże sprawa jest bardziej skomplikowana i jednowymiarowe spojrzenie przedstawione powyżej nie jest wystarczające, gdyż należy na to spojrzeć zarówno z poziomu kontroli, jak i sposobu lokalizacji. Tak wiec podział centralizacja i decentralizacja odnosi się stricte do poziomów kontroli danych/sieci, czyli de facto czy gdzie mieści się jurysdykcja danego systemu. Z kolei dystrybucja (rozproszenie) odnosi się do do zróżnicowania lokalizacji danych/systemu.
Z punktu widzenia kontroli, w systemie scentralizowanym kontrolę sprawuje tylko jedna jednostka (np. osoba lub przedsiębiorstwo). Oznacza to, że decyzje podejmowane są przez jedną jednostkę. W systemie zdecentralizowanym nie ma jednej jednostki kontrolującej, brak centralnego właściciela. Zamiast tego, kontrola jest dzielona pomiędzy kilka niezależnych podmiotów. Decyzja w takim systemie jest podejmowana w oparciu o jakiś mechanizm konsensusu/zgody.
Z punktu rozłożenia danych w systemie centralnym /nie-rozproszonym wszystkie części systemu/danych znajdują się w tej samej lokalizacji fizycznej. Z kolei w systemie rozproszonym części systemu istnieją w oddzielnych lokalizacjach. Są one rozproszona (czyli powielone), a więc zapisane jednocześnie na wielu urządzeniach komputerowych (węzłach).
W systemie scentralizowanym wszyscy użytkownicy są podłączeni do centralnego właściciela sieci lub “serwera”. Centralny właściciel przechowuje dane, do których dostęp mają inni użytkownicy, a także informacje o samych użytkownikach. Scentralizowany system jest łatwy do skonfigurowania i może być szybko rozwijany, ma on jednak istotne ograniczenia. W przypadku awarii system nie działa prawidłowo, a użytkownicy mogą stracić dostęp do danych, a jego dostępność takiej sieci jest zależna od tego właściciela. Dochodzą do tego jeszcze obawy o bezpieczeństwo, łatwo zatem zrozumieć, dlaczego systemy scentralizowane nie są już pierwszym wyborem dla wielu organizacji. Z punktu bezpieczeństwa systemy rozproszone dostarczają właściwej ochrony przed utratą danych, jako że te same dane są przechowywane w wielu miejscach i synchronizowane. Oznacza to też, że proces transakcji nie jest w całości przeprowadzany w jednym miejscu. Przykładem systemu w pełni z-centralizowanego jest stacjonarny komputer z zainstalowanym Windowsem. Microsoft kontroluje aplikację i system operacyjny (scentralizowany). Zarówno aplikacje, jak i system operacyjny znajdują się na jednym komputerze, tzn. w jednej fizycznej lokalizacji (nie rozproszonej).
System rozproszony jest podobny do zdecentralizowanego, ponieważ nie ma jednego centralnego właściciela. Z kolei system rozproszony, ale scentralizowany może wydawać się sprzeczny, ale jeśli użyjemy powyższych definicji opartych na systemie kontroli i lokalizacji wszystko staje się bardzo wyraźne. Przykładem takiego systemu to dostawca usług w chmurze, oferujący usługę przechowywania danych. Fizycznie, te dane użytkownika mogą być współdzielone (albo powielane) na różnych maszynach/serwerach (w zależności od dostępności i stopnia niezawodności). Jednak niezależnie od miejsca, w którym znajdują się maszyny i urządzenia do przechowywania tych danych, dostawca usługi w chmurze nadal kontroluje je wszystkie. Dlatego są scentralizowane, a taka konfiguracja jest zarówno scentralizowana, jak i rozproszona.
Z kolei pierwsza aplikacja blockchain: protokół Bitcoin, jest zdecentralizowanym systemem do wymiany cyfrowej “gotówki”, który oparty został na technologii rozproszonej księgi rachunkowej. W konsekwencji blockchain Bitcoin nie może być zmieniony przez jedną jednostkę (zdecentralizowaną), jak również działa również jako sieć peer-to-peer niezależnych komputerów rozsianych po całym świecie (rozproszonych).
Podsumowując, istnieją różne stopnie decentralizacji i rozproszenia. Co ciekawe stopień decentralizacji i rozproszenia decyduje także o rodzajach blockchainów. I tak wyróżniamy blokchainy: publiczne, prywatne, korporacyjne i federacyjne. Tematyką tą zajmiemy się w jednym z przyszłych wpisów.
KONTROLA JAKOŚCI w BLOCKCHAIN
Jak już nakreśliliśmy blockchain to struktura danych, które dodawane są tylko na końcu. Każde nowe dane muszą zostać sprawdzone pod względem poprawności, tak aby integralność całego łańcucha bloków w sieci została zachowana, po czym zostają one dodane i blockchain zostaje zwiększony o nowa jednostkę. Ktoś jednak musi dokonać pracy aby dane zostały zweryfikowane i dodane do struktury. Obecnie większość blockchain-ów istnieje w formie rozproszonej, znaczy się w wielu identycznych wersjach, w wielu różnych miejscach na świecie. Każdy węzeł w sieci niezależnie może weryfikować i przetwarzać każdą transakcję i dlatego musi mieć dostęp do aktualnego stanu danej bazy danych. Rodzi się zatem pytanie, w jaki sposób wszystkie węzły osiągają konsensus (zgodność) co do danych? Jak utrzymać sieć podmiotów, które koncentrują się na tym samym celu, mając do dyspozycji wyłącznie wiadomości przesyłane pomiędzy nimi, bez uszkodzenia informacji przez jakich złośliwych aktorów w sieci?
Zanim pojawiły się łańcuchy bloków, nie było praktycznego sposobu na zabezpieczenie takowych danych przed przed manipulacją w sieciach rozproszonych. Dodatkowo zdecentralizowany system nie pozwala, aby żaden pojedynczy uczestnik sieci miał całkowitą kontrolę nad przebiegiem transakcji. Pojawienie się Bitcoina rozwiązało ten problem, za pomocą wprowadzenia mechanizmu zdecentralizowanego konsensusu, definiowanego jako powszechna zgoda między członkami danej społeczności. Celem takiego mechanizmu jest doprowadzenie do porozumienia wszystkich węzłów, czyli do wzajemnego zaufania, w środowisku, w którym węzły nie mają do siebie zaufania. Mechanizm ten zapewnia, że sieć pozostaje zsynchronizowana, a dane pozostają nienaruszone. Konsensus zapewnia także prawidłową kolejność w kwestii dopisywania bloków zgodnie z założeniami protokołu, a także zapobiega zjawisku tak zwanego podwójnego wydawania aktyw cyfrowych. To właśnie dzięki zawarciu konsensusu, mamy możliwość odejścia od centralnego zarządzania oraz oddać działalność “w ręce ludu”.
Istnieje wiele mechanizmów zdecentralizowanej zgody. Główne różnice w różnych mechanizmach konsensusu blockchain koncentrują się wokół tego, jak prawo do dodawania danych do łańcucha blokowego jest rozdzielane między uczestników danej sieci, oraz w jaki sposób dane te są weryfikowane przez sieć jako, dokładne rozliczenie transakcji. Są takie mechanizmy, gdzie wszyscy uczestnicy sieci rywalizują ze sobą o to kto pierwszy znajdzie magic number, są takie kto da więcej ten zatwierdza nowy block, są także takie w których zatwierdzanie odbywa się droga demokracji przedstawicielskiej. Rodzaje zdecentralizowanej zgody zostaną opisane w oddzielnym wpisie, gdyż jest to jedna z najważniejszych składowych technologii blockchain.
Jeszcze nowszym rozwiązaniem konsensusu jest struktura określana mianem zdecentralizowanej autonomicznej organizacji DAO. Jest to rodzaj reguł rządzących, mających postać szczególnego rodzaju inteligentnego kontraktu znajdującego się w przestrzeni cyfrowej. Celem takowego mechanizmu jest ustanowienie zarówno pozarządowej, jak i bezpaństwowej formy jednostki oraz zaprogramowanie nieobowiązujących zasad.
Podczas gdy publiczne łańcuchy blokowe mają tendencję do bycia zdecentralizowanymi, to prywatne łańcuchy blokowe są zazwyczaj kontrolowane przez jakiś podmiot. Jednak nawet “zdecentralizowane” łańcuchy blokujące Bitcoin i Ethereum zostały ocenione jako “niezbyt zdecentralizowane” w badaniu przeprowadzonym przez Cornell University. Badanie wykazało, że władza jest skoncentrowana wśród stosunkowo niewielu górników lub puli górniczych. Uznano również, że łańcuchy blokowe są mniej rozproszone, niż można by sądzić, ponieważ wiele węzłów łańcuchów blokowych jest fizycznie zlokalizowanych w zaledwie kilku dużych centrach danych.
Podsumowując blockchain (publiczny) to wspólny, wiarygodny i weryfikowany zapis transakcji, do którego dostęp ma każdy użytkownik sieci, ale nikt nie może go zmienić. Jest on zaszyfrowaną, chronioną, zabezpieczoną przez manipulacją, zdecentralizowaną bazę danych stanowiącą doskonałe miejsce do gromadzenia wartości, danych osobowych, umów, praw własności, a także upoważnień. Chociaż technologia łańcuchów blokowych kojarzy się nam obecne głównie z pieniądzem cyfrowym, jej potencjalne zastosowania są rzeczywiście rewolucyjne, o czym w kolejnych częściach Kryptolandi. Powyżej został wyjaśnione podstawy blockchain, a gdyby ktoś chciał wytłumaczyć jak działa blockchain swojemu dziecku to polecamy poniższe video.
The END
Bmen
Ps. Jeżeli podobał wam się artykuł, zachęcamy do ocenienia, skomentowania, podzielenia się przemyśleniami i za-linkowania lub podzielenia się via media.
DISCLAIMER / UWAGA! Niniejszy opracowanie (jak każde inne na tym blogu) ma charakter amatorskiej analizy, która ma na celu jedynie ogólnie przybliżenie czytelnikowi omawianego tematu. Analiza ta jest efektem dociekań autora, i jest na tyle szczegółowa/precyzyjna, na ile autor uznał za stosowne. Jest ona tylko prywatną opinią autora, nie stanowi żadnych rekomendacji inwestycyjnych, i nie może służyć jako podstawa decyzji inwestycyjno-biznesowych. W celach głębszego zrozumienia tematu, bądź też zdobycia profesjonalnej informacji, autor zachęca do sięgnięcia po prace specjalistów z danej dziedziny. Sam autor, na własne potrzebny, zebrał podstawowe informacje w tematyce po to, aby móc wyrobić sobie poglądy na interesujące go zagadnienia, a przetrawione wnioski są owocem tej pracy.
Niniejszym Team Bmen-ów zastrzega, że publikowane informacje i tezy są wolnymi przemyśleniami amatorów, na podstawie których nie mogą być konstruowane żadne roszczenia, przyrzeczenia, obietnice te rzeczowe czy też matrymonialne. W przypadku oblania się gorącą kawą lub zakrztuszenia rogalem podczas czytania tekstu Team nie bierze za to żadnej odpowiedzialności i renty płacić nie będzie!!
LITERATURA
- https://www.oecd.org/publications/how-s-life-in-the-digital-age-9789264311800-en.htm
- https://www.coindesk.com/world-economic-forum-governments-blockchain
- https://www.coindesk.com/santander-blockchain-tech-can-save-banks-20-billion-a-year
- https://www2.deloitte.com/mt/en/pages/technology/articles/mt-what-is-digital-economy.html
- https://www2.deloitte.com/global/en/pages/financial-services/articles/asset-servicing.html
- https://www.business-case-analysis.com/ledger.html
- https://www.ibm.com/blockchain/what-is-blockchain
- https://edu.pjwstk.edu.pl/wyklady/rpg/scb/index04.html
- http://uriasz.am.szczecin.pl/dydaktyka/access/bazy_danych.htmld
- https://stormit.pl/struktury-danych/
- https://steemit.com/cryptocurrency/@tokenzone/which-cryptocurrency-is-most-decentralized
- https://www.ilovecrypto.pl/blog/rozne-znaczenia-decentralizacji/
- https://www.finra.org/sites/default/files/2017_BC_Byte.pdf
- https://www.oecd.org/finance/OECD-Blockchain-Primer.pdf
- https://101blockchains.com/blockchain-vs-linked-list/
- https://vitalflux.com/blockchain-linked-list-like-data-structure/
- https://privatekeys.org/2018/04/17/anatomy-of-a-bitcoin-transaction/
- https://www.oreilly.com/library/view/mastering-bitcoin/9781491902639/ch07.html
- https://siotechworld.com/a-deeper-look-into-ethereums-technology/
- https://medium.com/@exantech/about-anonymity-in-account-based-blockchains-22a1ce5b0c7b
- https://cryptoapis.io/blog/utxo-vs-account-based-blockchains/
- https://medium.com/@jcliff/intro-to-blockchain-utxo-vs-account-based-89b9a01cd4f5
- https://www.seba.swiss/research/A-Beginner-s-Guide-to-Blockchain-Accounting-Standards
- https://medium.com/block-street/get-going-on-blockchain-12190d7d5cae
- https://www.blockchain.com/charts/n-transactions – BTC ilość transakcji
- TRANSAKCJE LIVE – https://live.blockcypher.com/btc/tx/c47340e35ac21421e0a7c6c774afa91e53d01e5d590e657790ed0e2c8c006a7d/
- Block Explorer – blockexplorer.com / blockchain.com /blockcypher.com / btc.com.


Brak komentarzy.