
We współczesnym świecie nikt nie wyobraża sobie życia bez komputerów, telefonów a większa część społeczeństw nawet bez portali społecznościowych, gdzie bardzo wiele o wszystkim i prawie wszystkich można się dowiedzieć. Jednym słowem informatyka i telekomunikacja mają olbrzymi wpływ na nasze życie, a trend jest tylko wzrostowy. Internet, słowo zadomowione w każdym języku, stało się częścią naszego życia, naszej codzienności. To dzięki tej sieci powstały miliony pomysłów biznesowych i nowych firm, a obecnie już niewiele przedsiębiorstwo byłoby w stanie bez niego przetrwać i dalej się rozwijać. Za pomocą tej globalnej infrastruktury przesyłane jest coraz więcej danych. A jak to mówią eksperci, dane są jak ropa naftowa przyszłości (Data = New Oil), a internet to rurociąg, do którego wszyscy mamy nieograniczony dostęp. Integracja, udostępnianie i analiza danych zaczyna mieć znaczący wpływ na rozwój gospodarczy, a cyfrowa ekonomia to już nie tylko termin książkowy, ale realna gałąź gospodarki generująca $ miliardowe zyski. Adaptacja cyfrowa stała się już zjawiskiem naturalnym, którego nie można zatrzymać. Technologia Blockchain to kolejna ewolucja w cyfrowej gospodarce, oraz poważne paliwo dla globalnego rozwoju. Blockchain, będący łańcuchem bloków z danymi, jest technologią, służącą do przechowywania oraz przesyłania informacji o transakcjach zawartych w Internecie. Rewolucja blockchain dopiero nadchodzi, powstają setki start-upów, które przyciągają olbrzymi kapitał na rozwój i badania, a rządy wielu państw inwestują ogromne sumy pieniędzy w rozwój technologii. Chiny prowadzące w krypto wyścigu uruchomiły właśnie narodowy projekt sieci Blockchain (BNS), będącej kręgosłupem cyfrowej przyszłości Chin.WEF prognozuje że w 2025 aż 10% globalnego PKB będzie wytwarzane w oparciu o technologie Blockchain.
Z kolei poufność danych to zasadniczy komponent w cyfrowej gospodarce. Dlatego też kryptografia jest zasadniczym elementem obecnych systemów bezpieczeństwa, począwszy od wojskowości, przez dyplomację, po codzienny użytek miliardów zwykłych zjadaczy chleba. Jest ona bardzo ważna gdyż dostarcza znacznego zwiększenia bezpieczeństwa transmisji i przechowywania danych. W ostatnich latach zakres kryptografii rozszerzył się poza kwestie poufności danych i obejmuje m.in. techniki sprawdzania integralności wiadomości/danych, uwierzytelniania tożsamości nadawców i odbiorców poprzez podpisy cyfrowe, metody interaktywnych dowodów oraz bezpiecznych obliczeń. Dostarcza też procesów autoryzacji, czyli potwierdzenia tożsamości na podstawie loginu i hasła dla logowania się do wszelakich usług internetowych (poczta email, bankowość elektroniczna itp). Czym jest kryptografia i na jakiej zasadzie działa zostało opisane w poprzedniej części sagi o KryptoLandii.
Spójność i integralność danych stanowi z kolei podstawę bezpieczeństwa informacji i ochrony danych. Pojęcie integralności danych staje się coraz bardziej powszechne, a sama integralność realizuje funkcje gwarantującą niezmienność przetwarzanej informacji, czyli zapewnia, że dany przekaz w żaden sposób nie został naruszony. Zmiany takowe mogą nastąpić w przekazie (będąc np. kwestią przypadkowego błędu w transmisji) jak i być efektem celowych działań związanych z przemyślanym atakiem, gdzie Man In The Middle (MITM), czytaj złośliwy użytkownik przechwytuje dokument zmieniający niektóre dane i przekazuje je do pierwotnego odbiorcy. Integralność danych jest przeciwieństwem ich uszkodzenia. Usługa integralności jest jedną z czterech podstawowych usług ochrony informacji. Pozostałymi są uwierzytelnienie, poufność i niezaprzeczalność. O ile te ostatnie wymienione usługi ochrony informacji nie są zupełnie niezależne od siebie, tak już usługa integralności pełni szczególną rolę, jako że bez niej nie ma możliwości prawidłowej realizacji pozostałych usług. Dlatego też bez zapewnienia integralności nie ma sensu budowanie jakiegokolwiek systemu informatycznego. Sprawdzanie poprawności danych jest warunkiem wstępnym dla integralności danych. Narzędziem pozwalającym zapewnić integralność danych i bezpieczeństwo przekazu są kryptograficzne funkcje skrótu (cryptographic hash function), zwane także hashami kryptograficznymi.
HASZOWANIE
Haszowanie jest procesem konwersji dowolnych danych wejściowych (input) o dowolnej długości na ciąg tekstu o stałej długości przy użyciu funkcji haszującej. Funkcja haszująca zwana też funkcją skrótu jest rodzajem funkcji matematycznej, która przyjmuje dowolną formę (i wielkość) danych wejściowych (liczby, słowa, pliki tekstowe, multimedialne itd) i przetwarza je na dane wyjściowe (output) o stałej długości. Jest to więc proces przyporządkowania określonej wartości dla danych wejściowych. Wartość zwracana przez funkcję skrótu nazywane jest wartością hash, kody hash, digest, lub po prostu skróty. Hash jest ciągiem liter i cyfr o stałej długości, który można w uproszczeniu nazwać “cyfrowym odciskiem palca” danych cyfrowych. Informatycy mówią z kolei, że haszowanie to mapowanie danych o dowolnej wielkości na określoną długość.

Source: Lisk Academy
Praktycznie każdy rodzaj danych może być skrócony/haszowany, bez względu na rozmiar i rodzaj danych wejściowych. Mogą to być np. dane podsumowujące transakcje bankowe, poczta elektroniczna, dowolnego rodzaju pliki, tekstowe, zdjęcia, audio czy nawet wideo. Dla przykładu poniżej wartość hash dla tekstu witryny “bogaty.men”.
SHA256(bogaty.men) = 08010509a8d2ccdf350bcdb1c66a7f9bd7f6aa2d04d1f6570f1ac969ee7fc9cf
Co ważne typ i wielkość danych wejściowych nie ma wpływu na długość danych wyjściowych. Oznacza to, że “waga” danych wejściowych nie ma znaczenia, gdyż i tak otrzymamy hash tego samego formatu ciąg alfanumeryczny. Przykładowo, gdybyśmy skrócili/zhaszowali tekst np. “bogaty.men” za pomocą jakiegoś algorytmu (np. SHA-256 albo Keccak-256) to otrzymalibyśmy N bitów (przykładowo 256) jako jego wartość hash (długość N zależna jest od wybranego algorytmu). Gdybyśmy później tym samym algorytmem zhaszowali całą książkę (np. Wojna i Pokój Tołstoja) lub cały plik wideo (np. Seksmisja) to nadal otrzymalibyśmy 256 bitów w hashu/skrócie, zakładając że użyliśmy tego samej funkcji haszującej. Różne algorytmy dostarczają różnego formatu na wyjściu, o czym później.
IDEALNA FUNKCJA MIESZAJĄCA
Doskonała funkcja mieszająca powinna charakteryzować się tym, że wygenerowany przez nią skrót/hash jest unikalny i niemożliwy do odwrócenia. Z tego powodu funkcja taka charakteryzuje się kilkoma cechami.
Szybkość działania
Funkcja powinna być szybka obliczeniowo, co oznacza że powinna być w stanie bardzo szybko “policzyć” hash z danych wejściowych. Jeżeli proces nie będzie wystarczająco szybki, wtedy cały system traci na wydajności, albo nie będzie mógł pracować w czasie rzeczywistym. Szybkość algorytmu jest to ważny parametr, gdyż ma bezpośredni wpływ na wydajność sprzętową czy też na hashrate górników kopiących krytpo-waluty.
Determinizm
Funkcja ta jest deterministyczna, co oznacza że bez względu na to, ile razy wprowadzone zostaną te same dane, to zawsze wygenerują one ten sam wynik. Oznacza to, iż dopóki dane wejściowe się nie zmienią, hash pozostaje taki sam. Jest to krytyczne, ponieważ jeśli za każdym razem uzyskiwany byłby inny hash, to późniejsza identyfikacja /porównanie danych wejściowych za pomocą Hash byłaby bezużyteczna. Funkcja haszująca generuje stałą długość skrótu, która jest określana jako za pomocą N bitów, zależnie od użytego algorytmu.
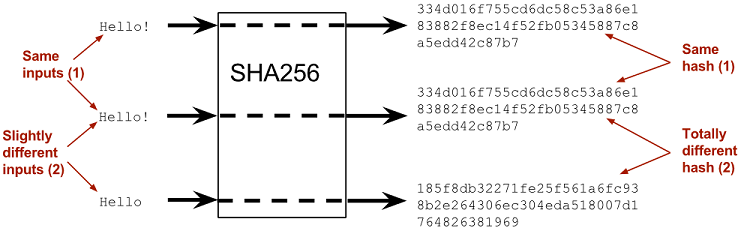
Source: https://freecontent.manning.com/cryptographic-hashes-and-bitcoin/
The Avalanche Effect
Funkcja ta jest niezwykle czuła na niewielkie zmiany wejściowe. Dlatego też powinna mieć zaimplementowany mechanizm “Efektu Lawiny”. W przypadku nawet niewielkich zmian danych wprowadzonych do funkcji, zmiana ta wywołuje drastyczne zmiany w haszu wyjściowym. Jest to krytyczna cecha, gdyż pomaga w uodpornieniu na obraz wstępny. W implementacji “efektu lawinowy” wykorzystywana jest koncepcja Efektu Motyla. Pisząc kolokwialnie, jeżeli motyl pierdnie w Radomiu, to w Londynie spadnie wielki deszcz, będący wynikiem wiatrów wytworzonych przez motyla 🙂 Jeżeli szyfr blokowy lub funkcja kryptograficznego haszowania nie wykazuje w znaczącym stopniu efektu lawinowego, to ma on słabą randomizację, a zatem kryptoanalityk może dokonywać przewidywań dotyczących wejścia, znając jedynie wyjście. Tak więc nawet zmiana jednego znaku (np. z małej na dużą literę) czy cyfry powinna wygenerować kompletnie inny hash. Poniżej przykład dla “Bogaty.men” vs “bogaty.men”.
SHA256(bogaty.men) = 08010509a8d2ccdf350bcdb1c66a7f9bd7f6aa2d04d1f6570f1ac969ee7fc9cf
SHA256(Bogaty.men) = 2d8be19b6b864921169e780af306b3acac4e45b2b005ee129164287c30096bfd
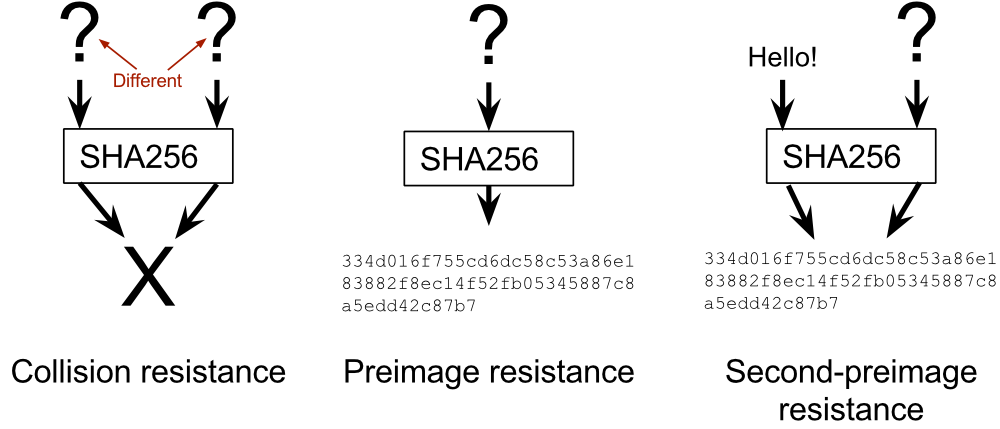
Pre-image Resistance
Funkcje jest tak zaprojektowana aby działała jako funkcja jednokierunkowa, tym samym niemożliwa do odwrócenia. Oznacza to, że można nią “skrócić” dowolne dane, ale nie można już odzyskać oryginalnej wiadomości na podstawie otrzymanego hashu. Funkcja skrótu jest uważana za odporną na tzw. pre-image, gdy istnieje bardzo małe prawdopodobieństwo, że ktoś będzie w stanie odnaleźć dane wejściowe, za podstawie konkretnego zestawu danych wyjściowych. Technicznie możliwe jest “odwrócenie” hashingu za pomocą metodą brut-force (zgadywanie i sprawdzanie), ale wymagana moc obliczeniowa czyni ten proces niewykonalnym. Czas takiego ataku zależny jest od długości hashu. Im dłuższa (w bitach) wartość hashu, tym więcej możliwości wszystkich kombinacji do sprawdzenia, a przy aktualnych długościach 256+bit przechodzimy z czasem w kierunku nieskończoności. Odtworzenie plików jest np. zwyczajnie nie możliwe bo jak odzyskać dane, skoro zostały one zwyczajnie zmielone i skrócone? Hash jest więc realnym procesem jednokierunkowym.
Bezkolizyjność i Second Pre-image Resistance
Funkcja ta nie dostarcza tego samego skrótu dla różnych danych wejściowych. Jeśli dwa różne pliki/dane wejściowe wytwarzają tę samą unikalną wartość haszu { h(‘abc’) == h(‘cab’) } to nazywane jest to kolizją i czyni to algorytm zasadniczo bezużytecznym. Jeżeli istnieją takie same hashe dla różnych danych wejściowych to funkcja unikalności przestaje istnieć. Dzięki tej właściwość niemożliwe jest znalezienie dwóch odrębnych danych wejściowych, które w wyniku zhaszowana wygenerują taki sam hash. Warto zauważyć, iż prawdopodobieństwa wystąpienia kolizji nie da się uniknąć. Dzieje się tak ponieważ, istnieje nieograniczona liczba danych wejściowych, a z drugiej strony ograniczona liczba danych wyjściowych. Dlatego ważna jest zależność, im więcej bitów N w hashu tym większa odporność na kolizje.
More Hash Bits = Higher Collision Resistance
Popularne funkcje hashowe generują wartości pomiędzy 160 a 512 bitami.
Source: https://freecontent.manning.com/cryptographic-hashes-and-bitcoin/
Second Pre-image Resistance jest wariancją cechy bezkolizyjności. Różnica pomiędzy tymi dwoma charakterystykami jest taka, że w przypadku bezkolizyjności hash wyjściowy nie jest znany, a funkcja ma gwarantować, że dwa dowolne wejścia nie wygenerują takiego samego skrótu, a w second pre-image resistance hash jest znany, a funkcja ma gwarantować że żadne inne dane wejściowe po skróceniu nie będą miały takiej samej wartości (identycznego) hashu.
FUNKCJA ZA-MIESZANIA
Funkcje mieszające powstały w wyniku konieczności “kompresji” danych w celu zmniejszenia ilości pamięci potrzebnej dla przechowywania dużych plików w pamięci. Unikalny skrót zajmuje bardzo mało miejsca i może reprezentować “duże wagowo” dane. Z czasem drugorzędna korzyść szybkiej identyfikacji przybrała na znaczeniu, a niepowtarzalne identyfikatory pozwoliły na nowe zastosowania kryptografii. Pierwsze projekty kryptograficznej funkcji skrótu pochodzą z końca lat 70. Na początku lat 90s opublikowane zostały dwa algorytmy MD5 i SHA-1, które bardzo szybko zyskały na popularności i zaczęły być używane w coraz większej liczbie zastosowań, w efekcie czego szybko zyskały określenie “Swiss army knifes” kryptografii.
Funkcja haszująca/mieszająca to nic innego jak algorytm, którego zadaniem jest obliczanie skrótu. Algorytm to z kolei nic innego jak zestaw instrukcji wykonywanych krok po kroku. Istnieją różne rodzaje algorytmów haszujących, ale podobnie jak algorytmy szyfrów symetrycznych wszystkie opierają się na matematyce dyskretnej.
Typowymi operacjami używanymi w takich funkcjach są zazwyczaj operacje na bitach (negacja NOT !, dodawanie OR |, iloczyn AND &, czy dopełnienie XOR ^, przesuniecie lewo/prawo << / >>), rotacja lewo/prawo <<< / >>>), operacje dodawania i mnożenia czy też używanie tabel Lookup (np. liczby pierwsze i magiczne, S-Box, P-Box). Operacje te są stosowane albo do pojedynczych bajtów albo do całych bloków bajtów. Ponadto są one szybkie, deterministyczne i łatwo dostępne na większości architektur procesorów, co czyni je idealnymi do implementacji funkcji haszującej. W celu dogłębnego mieszania danych większość algorytmów wykorzystują procesy iteracyjne, gdzie dany zestaw danych jest przetwarzany wielokrotnie (powtarzany np. 80 razy). Dla przykładowego zilustrowania operacji funkcji mieszania poniżej pokazane są wewnętrzne struktury dla legendarnych już algorytmów MD5 i SHA-1.
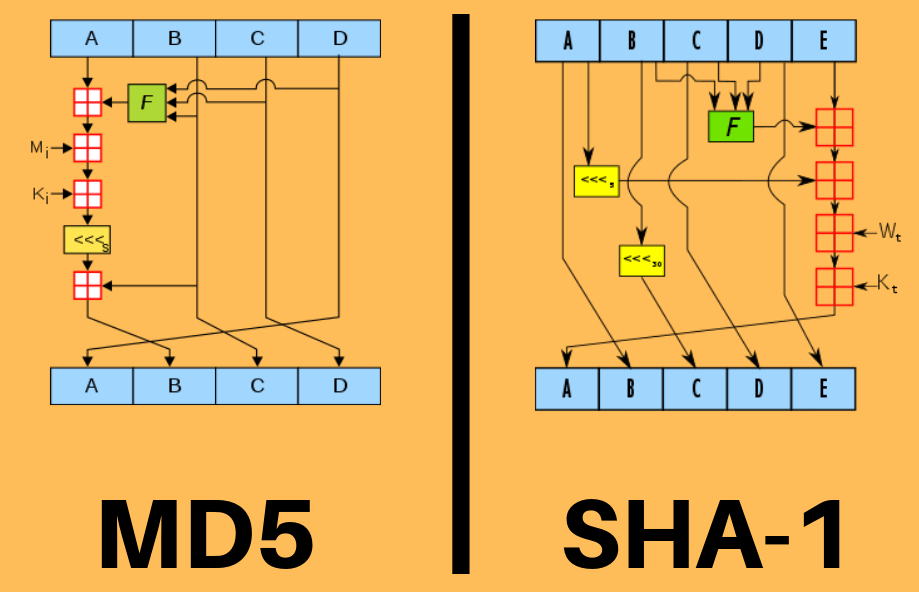
Source: https://techdifferences.net/difference-between-md5-and-sha-1/
Algorytm MD5 dostarcza na wyjściu hash o długości 128 bitów, podczas gdy SHA-1 już 160 bitów. Z kolei stosowany w Bitcoinie algorytm SHA2-256 jest już o wiele bardziej skomplikowany i ma strukturę przekształceń jak poniżej.
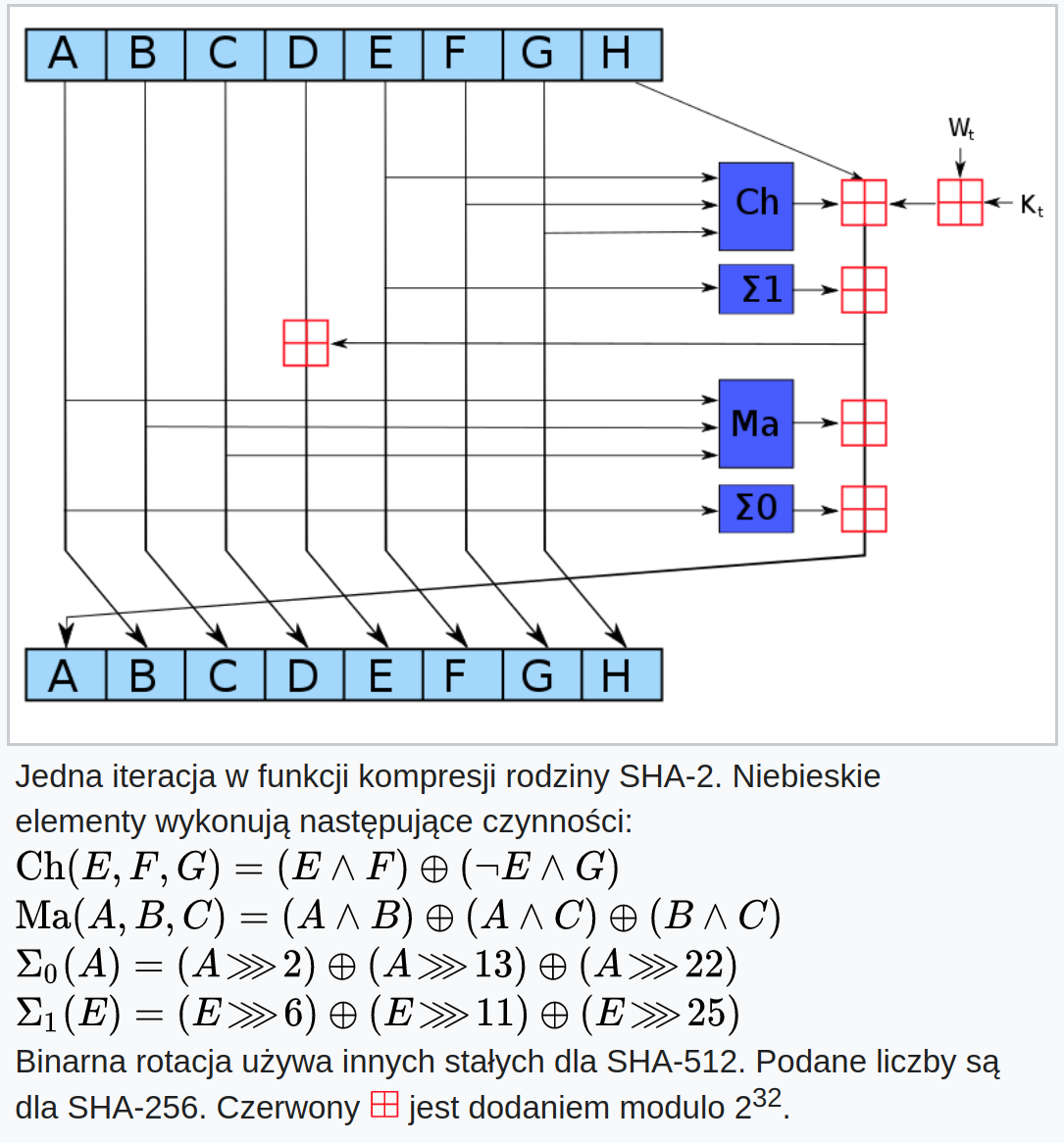
Source: https://pl.wikipedia.org/wiki/SHA-2
Warto w tym punkcie nakreślić różnice między szyfrowaniem i haszowaniem. Oba procesy biorą ciąg użytecznego tekstu i przekształcają go w coś zupełnie innego. I tutaj podobieństwa się zasadniczo kończą. Algorytmy haszujące są bowiem funkcjami, które generują wynik o stałej długości z dowolnego wejścia. Oznacza to, że haszowanie różni się od szyfrowania tym, że po zaszyfrowaniu dokument ma podobny rozmiar, podczas gdy zhaszowany dokument ma zazwyczaj rozmiar mniejszy niż oryginał. Oznacza o że “waga” wejściowa i wyjściowa dla szyfrowania są sobie mniej/więcej równe, podczas gdy dla haszowania nie ważne jaką”wagę” ma wejście, wyjście ma zawszą taką samą “wagę” określaną przez algorytm, bardzo często znacznie mniejszą niż dane wejściowe.
Zarówno szyfrowanie i haszowanie może przetwarzać nieograniczoną ilość informacji. Jednakże haszowanie zaprojektowane jest jako algorytm szyfrowania jednokierunkowego, co powoduje że nie można odszyfrować prze-konwertowanych danych, ponieważ suma skrótu nie jest wystarczającą do jego odszyfrowania, jak ma to miejsce w procesie szyfrowania w klasycznej interpretacji tego procesu. Nie ma znaczenia czy dane wejściowe mają 8 bajtów czy zdjęcie 8 Mega Bajtowe, hash będzie zawsze miał długość N bajtów, np. 256 jak w SHA-256 (256 bitów = 32 bajty). Aby zapisać informacje o pliku, potrzebne są jedynie 32 bajty, co jest o wiele mniejsze w porównaniu z rozmiarem 8 megabajtowego zdjęcia. Jak to jest możliwe, że dane o bardzo różnych długościach i “wagach” dostarczają tak samo długiego skrótu?
Większość istniejących algorytmów mieszania została utworzone za pomocą konstrukcji Merkle-Damgard. Mając daną funkcję skrótu operującą na niewielkim bloku danych, można rozszerzyć jej działanie i skonstruować funkcję operującą na dowolnie dużej ilości danych wejściowych. W ten sposób staje się możliwe obliczenie wartości skrótu dla wiadomości o dowolnej długości danych wejściowych. Proces ten jest realizowany poprzez podzielnie danych wejściowych na jednolite bloki bitów (np. 512 dla SHA-256). Jeżeli dane wejściowe nie są wielokrotnością rozmiaru bloku to zastosowane zostają techniki wypełniania (padding), tak aby całe wejście było podzielone na bloki danych o stałym rozmiarze. Każdy blok jest poddawany jednokierunkowej kompresji, w wyniku czego długość danych jest znacznie zmniejszona. Wyjście pierwszego bloku danych jest podawane jako wejście wraz z drugim blokiem danych itd. Jeżeli gdziekolwiek w komunikacie zostanie zmieniony jeden bit, to zmienia się cała wartość hash. Rozmiar bloku danych różni się w zależności od algorytmu. Poniżej pokazana jest struktura działania takiej operacji, oraz przykładowe ( i bardzo uproszczone) obliczenia dla ogólnej struktury Merkle-Damgard.
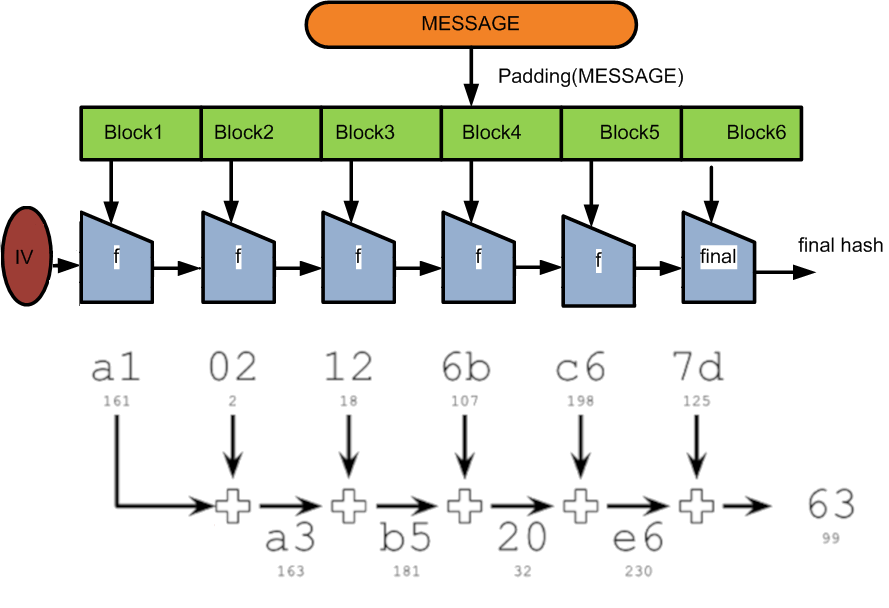
Source: Source: https://www.wikiwand.com/en/Merkle%E2%80%93Damg%C3%A5rd_construction / https://freecontent.manning.com/cryptographic-hashes-and-bitcoin/
Najnowsze algorytmy z serii SHA-s używają nowej konstrukcji Sponge (“budowa z gąbki” ). Zainteresowanych tematem odsyłamy do wideo: Cryptographic sponge construction.
ALGORYTMY ZA-MIESZANIA
Dostępnych jest wiele różnych algorytmów haszujących, a nowe pojawiają się szybko. Ponieważ moc obliczeniowa komputerów szybko rośnie stają się one bardziej skomplikowane i dłuższe. Najnowsze algorytmy z rodziny SHA to seria SHA-3, będące przedstawicielami rodziny haszyszów “Keccak”. Keccak jest zwycięzcą konkursu SHA-3 NIST i jest on oparty na kryptograficznej strukturze sponge.
Wartość i długość skrótu dla funkcji skrótu zależna jest od zastosowanego algorytmu. Przykładowo funkcja skrótu dla “www.bogaty.men” uzyskana z rożnych współczesnych algorytmów wygląda następująco:
MD5: 120ebe304cefa8329c218e6649708893
RIPEMD160: 6e66ce01d71c8f55a70204e9a2c92bf2284e9d4
SHA2-256: aa597ad8d6ffd40976270bf1b9c1f5917a9a95cab445f5b1e7842ccf8945b3
SHA3-256: 1ba2f8e6617aa67ec4268e4920343c6de9784604d13927fbf567f88c8ea04d39
Keccak256: d5c091e796ab61941f57cd2f3589c6834c55ccd18038aafc6f4f06d86a10d7e4
SHA2-512: af8ecd0b499194d67c0491c8accc2ea61e70240b8e468b6857bab01ee8b1e1995a09ca399d46ac4d3a0ea5e6aaf5cbb6b0d5b3f33fd16f897000a6fe9bbdf43b
BLAKE2B: b838b9031326b45f6e0489ad52a8e201fb286e8c956e0b79ae28ba20bb270a2df263f800f1ed2808dca72154c9ef31f5bcaa57e9c2e4a25a9c63c1f731de1535
Whirlpool: 23d61f1a20e415b1758b84c63d9c7981d4486ad69b472c6f19e31295ba6af9cf2fce545726faafa1d5b8e7e0c1c0af5d356abf32a51535007f48f4545259d6f7
Dla zainteresowanych wyliczaniem skrótów poniżej kilka kalkulatorów hash online:
- https://www.tools4noobs.com/online_tools/hash/
- https://www.fileformat.info/tool/hash.htm
- https://md5calc.com/hash
- https://xorbin.com/tools/sha256-hash-calculator
Co ciekawe wiele algorytmów zostało już w teorii, a nawet praktyce złamanych, przez co stały się mało użyteczne, jako że nie posiadają już deklarowanego poziomu bezpieczeństwa. Listę ataków zarówno tych teoretycznych jak i praktycznych można znaleźć w linkach poniżej.
- https://en.bitcoinwiki.org/wiki/Comparison_of_cryptographic_hash_functions
- https://en.bitcoinwiki.org/wiki/Hash_function_security_summary
Uważa się, że najsilniejsze obecnie algorytmy miksujące to SHA3-512, RIPEMD-320, Whirlpool, BLAKE2b(512-bit). Kryptowaluta Bitcoin do swojego protokołu kopania (PoW mining) używa algorytmu SHA – 256, z kolei Ethash jest algorytmem skracania PoW dla Etherium. Ten ostatni wykorzystuje algorytm Keccak, który został już ostatecznie znormalizowany do SHA-3. Scrypt jest kolejnym algorytmem PoW, który jest używany przez wiele walut kryptograficznych. Jest on prostszą i szybszą alternatywą dla SHA-256. Inne z popularnych algorytmów haszujących dla kryptowalut to Equihash, Cryptonight, X11, Blake-256, HEFTY1, Quark, lub CryptoNight.
CYFROWY ODCISK PALCA
Zasadnicza cechą funkcji haszującej jest jej stały i unikalny wynik dla tego samego obiektu wejściowego. Wyjściowy Hash to niepowtarzalny identyfikator. Z tego powodu nazywany jest on potocznie “cyfrowym odciskiem wiadomości”.
HASH value= Fingerprint for the Data = Data ID
Tak jak człowiek ma unikalną datę/czas urodzenia oraz unikalny kształt linii papilarnych tak dane mają unikalny odcisk cyfrowy. Cyfrowy odcisk palca dla danych, plików a nawet dokumentów. Odcisk ten uzyskiwany jest właśnie poprzez funkcje haszowania. Hash jest po prostu unikalnym identyfikatorem danych wejściowych, coś ala cyfrowym paszportem danych.
Source: https://hive.blog/education/@dblockchainblog/hash-cryptography-part-1-understanding-sha256-usage
To właśnie z powodu swojej funkcji unikalności generującej cyfrowe ID funkcja haszującą jest motorem napędowym technologi Blockchain.
HASH jako Strażnik BLOCKCHAINA
Haszowanie wykorzystywane jest w wielu procesach. Właściwie to funkcja skrótu jest “koniem pociągowym” dla nowoczesnej kryptografii. Jednym z najważniejszych zastosowań funkcji haszowania jest sprawdzanie czy plik/dane nie zostały zmienione, przez co możliwe jest potwierdzanie autentyczności. Przykładowo, do dokumentu wysłanego pocztą elektroniczną może zostać dołączony jego hash, tak aby odbiorca mógł sprawdzić czy otrzymał niezmieniony dokument. Algorytmy kryptograficznej funkcji skrótu są również szeroko stosowane w aplikacjach związanych z bezpieczeństwem informacji w takich zastosowaniach jak np. uwierzytelnianie wiadomości przesyłanych w formie cyfrowej czy też potwierdzanie cyfrowej tożsamości. Hashing zwiększa też bezpieczeństwo procesów autoryzacyjnych, jako że służy do przechowywania haseł. Zamiast zapisywania hasła w postaci przejrzystej, w większości przypadków procesy logowania przechowują wartości hash dla haseł w plikach/bazach danych. Podczas logowania do komputera czy serwisu online, wprowadzone hasło jest haszowane i porównywane z zapisanym w bazie danych hashem hasła. Jeżeli oba są identyczne to logowanie jest udane. Hashing wykorzystany jest również do indeksowania danych w tabelach hash, do wykrywania duplikatów lub jako narzędzie sumy kontrolnej (można wykryć, czy przesłany plik nie doznał przypadkowego lub celowego uszkodzenia danych podczas transmisji).
Procesy haszowania są najważniejszą częścią technologii Blockchain, jako że służą one do tworzenia jego historii, oraz co bardzo ważne zabezpieczają przed jej zmianą. Technologia ta została tak zaprojektowana, aby dane/transakcje były niezmienne i nieodwracalne po zatwierdzeniu bloku. Niezawodność i integralność łańcucha blokowego opiera się na tym, że prawdopodobieństwo jakichkolwiek zmian (zafałszowanie, usunięcie danych/transakcje) w historii danego Blockchaina jest bardzo niewielkie, a kamieniem węgielnym całej technologii i kluczowym elementem w utrzymaniu tej niezawodności jest właśnie hashing.
Blockchain to nic innego jak łańcuch bloków zawierających jakieś dane. Połączone one są sobą za pomocą wskaźników hashowych, w wyniku czego otrzymujemy właśnie łańcuch bloków. W programowaniu wskaźniki są zmiennymi, które przechowują adres innej zmiennej (wskazują na tą zmienną). Wskaźnik hash jest z kolei specjalną klasą wskaźników, która wskazuje na hash wartości zmiennej, na którą jest on skierowany. Kluczową funkcją łańcucha blokowego jest to, że opiera się on właśnie na hashowych wskaźnikach. Każdy nowy blok w całym łańcuchu składa się z nagłówka (header), danych (np. lista transakcji, gdzie podany jest odbiorca, nadawca oraz wartość przesyłanej kwoty czy dane do inteligentnego kontraktu), a także z hashu wyliczonego dla transakcji/danych dla aktualnego bloku oraz wskaźnika hashu do poprzedniego bloku w łańcuchu blokowym. Dane wejściowe do nowego bloku reprezentują więc wszystko co wydarzyło się w historii danego łańcucha bloków, od bloku genezy (pierwszego) do tego momentu, a więc każdą pojedynczą transakcję w historii bloku. Nowy block jest dalej przetwarzany w wyniku czego powstaje jego unikalny hash, który dalej będzie używany w następnym bloku w łańcuchu. Każdy nowy blok jest więc funkcją starego bloku, a każdy stary blok jest zawarty w nowym bloku. Blockchain jest po prostu cyfrową księgą hashów, która wykorzystuje do zatwierdzeń jakiś dowód z-decentralizowanej zgody. Oba mechanizmy dostarczają strukturę danych o matematycznej identyfikowalności i niełamliwości.
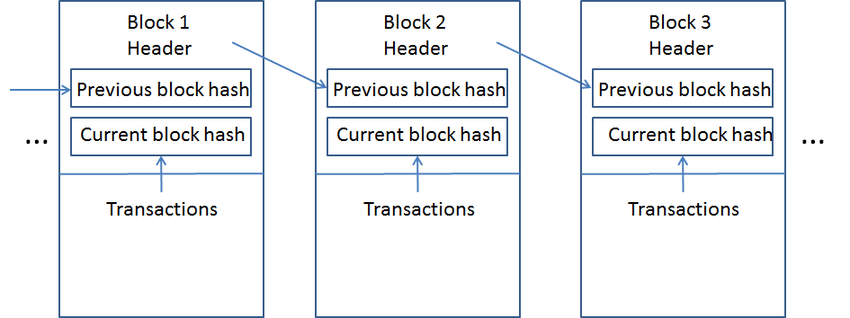
Source: https://www.researchgate.net/figure/A-simple-Blockchain-structure_fig2_325841576
Można powiedzieć, że w łańcuchu blokowym hashe używane są do reprezentacji bieżącego stanu rzeczy, a dokładniej stanu łańcucha blokowego. Jak już zostało powiedziane, hash dla nowego bloku jest oparty na wszystkich poprzednich hashach, które miały miejsce w danym łańcuchu blokowym. Ponieważ funkcje mieszające są bardzo “czułe” na jakiekolwiek zmiany danych wejściowych, zmiana dowolnej zmiennej dla któregokolwiek z haszyszów w danym bloku spowodowałaby efekt domina, i zmieniłoby to wszystkie poprzednie transakcje w bloku. Spójność hashów w sposób jednoznaczny stwierdza autentyczność, iż mamy do czynienia z oryginałem. W tym tkwi niepodważalne bezpieczeństwo technologii łańcuchów blokowych. Zmiana jakiegokolwiek rekordu, który wcześniej miał miejsce na łańcuchu blokowym, zmieniłaby wszystkie skróty, czyniąc je fałszywymi i nieaktualnymi. Jest to więc praktycznie niemożliwe w sieciach zdecentralizowanych, gdy weźmie się pod uwagę przejrzystą strukturę łańcucha blokowego, oraz fakt że modyfikacje musiałyby być dokonywane na widoku całej zdecentralizowanej sieci. W rzeczywistości prawie wszystkie protokoły odpowiedzialne za działanie kryptowalut i ich sieci polegają na funkcjach haszujących, w celu tworzenia łańcucha bloków. To właśnie koncepcja hashingu jest główną częścią tego, co sprawia, że łańcuchy blokowe są rewolucyjne i unikalne.
Drugą ale także ważna rolą funkcji haszujących jest tworzenie adresów publicznych. Odbywa się to za pomocą kombinacji algorytmów hashowych np. SHA-256 i RIPEMD-160 dla Bitcoina. Proces ten jest inicjowany poprzez wygenerowanie klucza prywatnego z pomocą multiplikacji ECC (Elliptical Curve Cryptography). W kolejnym etapie klucz ten jest przepuszczany przez SHA-256, a następnie dalej haszowany przez RIPEMD-160 w celu wygenerowania HASH_1. Ten z kolei następnie znów przetwarzany przez SHA-256, a pierwsze siedem cyfr tego nowego haszu staje się HASH_2. HASH_1 i HASH_2 są następnie łączone i tak właśnie powstaje adres publiczny, dla korespondującego adresu prywatnego.
Funkcja haszująca jest jednym z elementów, które tworzą serce i duszę technologii krypto-walut i łańcuchów blokowych. Połączona razem z zdecentralizoanym mechanizmem zgody, oraz z podpisem cyfrowym staje się ciałem i duszą dla dowolnej waluty cyfrowej. Tematem podpisu cyfrowego zajmiemy się w kolejnej części KryptoLandii.
The END
Bmen
Ps. Jeżeli podobał wam się artykuł, zachęcamy do ocenienia, skomentowania, podzielenia się przemyśleniami i za-linkowania lub podzielenia się via media.
DISCLAIMER / UWAGA! Niniejszy opracowanie (jak każde inne na tym blogu) ma charakter amatorskiej analizy, która ma na celu jedynie ogólnie przybliżenie czytelnikowi omawianego tematu. Analiza ta jest efektem dociekań autora, i jest na tyle szczegółowa/precyzyjna, na ile autor uznał za stosowne. Jest ona tylko prywatną opinią autora, nie stanowi żadnych rekomendacji inwestycyjnych, i nie może służyć jako podstawa decyzji inwestycyjno-biznesowych. W celach głębszego zrozumienia tematu, bądź też zdobycia profesjonalnej informacji, autor zachęca do sięgnięcia po prace specjalistów z danej dziedziny. Sam autor, na własne potrzebny, zebrał podstawowe informacje w tematyce po to, aby móc wyrobić sobie poglądy na interesujące go zagadnienia, a przetrawione wnioski są owocem tej pracy.
Niniejszym Team Bmen-ów zastrzega, że publikowane informacje i tezy są wolnymi przemyśleniami amatorów, na podstawie których nie mogą być konstruowane żadne roszczenia, przyrzeczenia, obietnice te rzeczowe czy też matrymonialne. W przypadku oblania się gorącą kawą lub zakrztuszenia rogalem podczas czytania tekstu Team nie bierze za to żadnej odpowiedzialności i renty płacić nie będzie!!
LITERATURA
- https://spectrum.ieee.org/computing/software/china-launches-national-blockchain-network-100-cities
- http://www3.weforum.org/docs/WEF_Building-Blockchains.pdf
- https://www.trustedsec.com/blog/passwordstorage/
- https://www.streetdirectory.com/etoday/what-is-the-strongest-hash-algorithm-ejcluw.html
- https://newtech.law/pl/hash-czyli-cyfrowy-odcisk-palca-pliku-komputerowego/
- https://kl2217.wordpress.com/2011/07/21/common-hashing-algorithms/
- https://cheapsslsecurity.com/blog/decoded-examples-of-how-hashing-algorithms-work/
- https://www.tutorialspoint.com/cryptography/cryptography_hash_functions.htm
- https://freecontent.manning.com/cryptographic-hashes-and-bitcoin/?
- https://www.partow.net/programming/hashfunctions/
- https://steemit.com/bitcoin/@liquidtravel/cryptographic-hash-functions
- https://www.youtube.com/watch?v=2BldESGZKB8
- https://www.youtube.com/watch?v=GI790E1JMgw
- https://blockgeeks.com/guides/what-is-hashing/
- http://www.unixwiz.net/techtips/iguide-crypto-hashes.html
- https://electriccoin.co/blog/lessons-from-the-history-of-attacks-on-secure-hash-functions/
- https://cryptobook.nakov.com/cryptographic-hash-functions/crypto-hashes-and-collisions
- https://cryptobook.nakov.com/cryptographic-hash-functions/secure-hash-algorithms
- http://www.unixwiz.net/techtips/iguide-crypto-hashes.html
- https://academy.ivanontech.com/blog/what-is-hashing-a-complete-guide-to-hashing


Komentarze ( 1 )